项目介绍
该项目主要用于现今互联网电商平台中使用Spark等技术开发的用来进行用户行为数据采集,然后对采集的数据进行分析,最后输出数据分析的结果,并通过可视化技术展示出来。
该项目主要由三部分组成,第一部分,我们通过仿照淘宝天猫的电商系统,搭建了一个简易版电商系统,实现了电商的一些简单功能,如用户登陆注册,添加购物车,下单购买等。第二部分,我们通过利用数据仓库相关知识,把收集的数据进行存储,分析,处理,得出我们想要的结果。第三部分,我们将分析之后的数据进行可视化展示。
项目需求及框架设计
电商系统需求分析:
电商系统主要作用是让商家和消费者能够在互联网上轻松便捷的实现商品交易,由于本项目主要的重点在于分析作为消费者的用户行为数据,因此,我们对于仿照的淘宝天猫电商系统的功能进行了适当的缩减,具体功能参照可以用来采集并分析的第一性原则,具体需求的分析,我们主要从下面三点考虑:1.商品展示方面,这方面的功能我们打算实现,对商品进行分类,用户可以选择自己想要的商品类别进行挑选,这样能便于用户节省时间,同时对于采集的数据也更具与针对性,直接筛选出用户的需求大方向,同时加入广告展示,我们打算采用轮播图来展示一些商家做出的活动广告,这样我们可以通过用户点击得出用户对于哪种活动更倾心,从而优化广告推荐。2.用户管理方面,用户的注册,登陆,这样方便采集各个地区的用户数据,从而我们可以更加对用户的需求由针对性的推荐。3.订单管理方面,用户的个人中心能够查看自己的订单,用户可以确定自己购买的商品信息。
数据仓库需求分析:
如今互联网的发展十分迅速,作为电商入驻商家,对于了解用户喜好,了解用户动向等方面的需求日益增长,因为只有了解了用户的喜好,才能做出更好的决策,了解用户对于产品的评价,喜好程度,具体哪方面的功能喜好,什么类型的产品更受用户欢迎,才能采取行动,不断优化自己的产品,实现优胜劣汰,不断进步,从而在互联网这样的大丛林中更好的生存下去。所以我们需要对用户在电商系统中的行为进行采集,分析,展示,来了解用户的喜好,从而进一步分析出产品的优缺点,不同产品的优劣,从而进行产品的迭代更替,这就需要我们对用户产生的数据进行采集,分析,输出展示,数据仓库要包含以上最基本的功能,才能实现为商家提供决策的需求,同时由于现今属于用户数据大爆炸时期,简单的数据库已经难以满足我们的需求,因此我们采取Hadoop大数据生态来完成上述功能。
可视化展示需求分析:
采集分析得到的数据结果,需要展示出来才能帮助商户更好的决策,因此我们将结果进行可视化展示就显得尤为重要,因为通过可视化,商家能够更好的了解用户需求,可视化将技术和艺术进行了完美的结合,我们可以借助可视化的展示,更加清晰高效的将用户数据分析结果传达给商家,商家同时也可以更快速的对于数据结果做出反应,可视化相比于传统的数据展示具有传播速度更快的好处,因为人对于具象的图像处理速度比抽象的数字处理信息速度要快出10倍,而复杂的数据关系,通过图表能让人一目了然。数据可视化的展示,能够将每一维度的值进行分类,排序,组合,这样商家可以从多维度的数据来作为决策的依据。受大脑记忆的限制,我们观察物体的时候,图像更便于我们理解要处理的信息,因为图像更有趣,更具象,直观,从而帮助决策者更加轻松处理来自四面八方,多维度的数据源。
项目框架
框架选择,系统设计总体规则
对于项目技术上面的选型,我们主要考虑的几点因素是:系统的简单性,我们需要尽量使得平台系统的操作简单化,这样方便系统的使用者更加容易的上手。针对性,因为我们主要是要实现对用户数据的分析,所以整个系统的实现要针对于这一目标。实用性,我们的系统设计要尽可能实用。同时我们还要考虑数据量大小,业务需求,行业内的经验,技术成熟程度,创新性,开发维护成本,总成本预算。
系统开发工具
电商系统
通过Spring+SpringBoot+Mybatis+Maven实现
数据仓库系统
数据采集传输:Flume,Kafka,DataX,Maxwell
数据存储:MySQL,HDFS,HBase,Redis
数据计算:Hive,Spark,Flink
数据查询:Presto,ClickHouse
任务调度:DolphinScheduler
集群监控:Zabbix,Prometheus
数据可视化系统
Superset,Sugar
系统开发流程
电商系统:
数据库设计:
address 地址表
2). admin 管理员表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | admin_id | 编号 | int | √ | × | × | NULL | |
| 2 | admin_name | 账户名 | varchar | 25 | × | × | × | NULL |
| 3 | admin_nickname | 昵称 | varchar | 50 | × | × | × | |
| 4 | admin_password | 密码 | varchar | 50 | × | × | × | NULL |
| 5 | admin_profile_picture_src | 头像地址 | varchar | 255 | × | × | √ | NULL |
3). category 类别表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | category_id | int | √ | × | × | NULL | ||
| 2 | category_name | 类别名称 | varchar | 20 | × | × | × | NULL |
| 3 | category_image_src | 类别图片 | varchar | 255 | × | × | × | NULL |
4). product 产品表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | product_id | int | √ | × | × | NULL | ||
| 2 | product_name | 产品名称 | varchar | 100 | × | × | × | NULL |
| 3 | product_title | 产品标题 | varchar | 100 | × | × | √ | NULL |
| 4 | product_price | 原价 | decimal | × | × | √ | NULL | |
| 5 | product_sale_price | 促销价 | decimal | × | × | × | NULL | |
| 6 | product_create_date | 创建日期 | datetime | × | × | × | NULL | |
| 7 | product_category_id | 类别id | int | × | × | × | NULL | |
| 8 | product_isEnabled | 是否可用 | tinyint | × | × | × | 0 |
5). productimage 产品图片表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | productimage_id | int | √ | × | × | NULL | ||
| 2 | productimage_type | 类型(0:概述图片 1:详情图片) | tinyint | × | × | × | NULL | |
| 3 | productimage_src | 图片地址 | varchar | 255 | × | × | × | NULL |
| 4 | productimage_product_id | 产品id | int | × | × | × | NULL |
6). productorder 产品订单表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | productorder_id | int | √ | × | × | NULL | ||
| 2 | productorder_code | 订单号 | varchar | 30 | × | × | × | NULL |
| 3 | productorder_address | 产品地址 | char | 6 | × | × | × | NULL |
| 4 | productorder_detail_address | 产品详细地址 | varchar | 255 | × | × | × | NULL |
| 5 | productorder_post | 邮政编码 | char | 6 | × | × | √ | NULL |
| 6 | productorder_receiver | 收货人 | varchar | 20 | × | × | × | NULL |
| 7 | productorder_mobile | 联系方式 | char | 11 | × | × | × | NULL |
| 8 | productorder_pay_date | 支付日期 | datetime | × | × | × | NULL | |
| 9 | productorder_delivery_date | 发货日期 | datetime | × | × | √ | NULL | |
| 10 | productorder_confirm_date | 确认日期 | datetime | × | × | √ | NULL | |
| 11 | productorder_status | 订单状态(0:待付款 1:待发货 2:待确认 3:交易成功 4:交易关闭) | tinyint | × | × | × | NULL | |
| 12 | productorder_user_id | 用户id | int | × | × | × | NULL |
7). productorderitem 产品订单详细表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | productorderitem_id | int | √ | × | × | NULL | ||
| 2 | productorderitem_number | 数量 | smallint | × | × | × | NULL | |
| 3 | productorderitem_price | 单价 | decimal | × | × | × | NULL | |
| 4 | productorderitem_product_id | 关联产品id | int | × | × | × | NULL | |
| 5 | productorderitem_order_id | 关联订单id | int | × | × | √ | NULL | |
| 6 | productorderitem_user_id | 关联用户id | int | × | × | × | NULL | |
| 7 | productorderitem_userMessage | 用户备注 | varchar | 255 | × | × | √ | NULL |
8). property 类别属性表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | property_id | int | √ | × | × | NULL | ||
| 2 | property_name | 属性名称 | varchar | 25 | × | × | × | NULL |
| 3 | property_category_id | 关联类别id | int | × | × | × | NULL |
9). propertyvalue 产品属性管理表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | propertyvalue_id | int | √ | × | × | NULL | ||
| 2 | propertyvalue_value | 属性值 | varchar | 100 | × | × | × | NULL |
| 3 | propertyvalue_property_id | 关联属性id | int | × | × | × | NULL | |
| 4 | propertyvalue_product_id | 关联产品id | int | × | × | × | NULL |
10). review 评论表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | review_id | int | √ | × | × | NULL | ||
| 2 | review_content | 内容 | mediumtext | 16777215 | × | × | × | NULL |
| 3 | review_createdate | 创建日期 | datetime | × | × | × | NULL | |
| 4 | review_user_id | 关联用户id | int | × | × | × | NULL | |
| 5 | review_product_id | 关联产品id | int | × | × | × | NULL | |
| 6 | review_orderItem_id | 关联订单详细id | int | × | × | × | NULL |
11). user 用户表
| 序号 | 字段 | 说明 | 数据类型 | 长度 | 自增 | 主键 | 允许空 | 默认值 |
| 1 | user_id | int | √ | × | × | NULL | ||
| 2 | user_name | 用户名 | varchar | 25 | × | × | × | NULL |
| 3 | user_nickname | 昵称 | varchar | 50 | × | × | × | NULL |
| 4 | user_password | 密码 | varchar | 50 | × | × | × | NULL |
| 5 | user_realname | 姓名 | varchar | 20 | × | × | √ | NULL |
| 6 | user_gender | 性别 | tinyint | × | × | × | NULL | |
| 7 | user_birthday | 出生日期 | date | × | × | × | NULL | |
| 8 | user_address | 所在地地址 | char | 6 | × | × | × | NULL |
| 9 | user_homeplace | 家乡 | char | 6 | × | × | × | NULL |
| 10 | user_profile_picture_src | 用户头像 | varchar | 100 | × | × | √ | NULL |
系统设计逻辑
数据仓库系统
数据仓库概念:
数据仓库是面向主题,集成的,稳定的,时变的一个数据集合,主要用来进行数据分析,从而帮助管理决策。
不同于数据库专注于某个或者多个项目,数据仓库会根据使用者的实际需求,把来自不同的数据源,包括但不限于数据库的数据,整合在一个比较高层次的阶段做整合,这些来源不同的数据都围绕着某一个主题进行处理分析,用统计出来的数据帮助使用者分析相关产品的情况,然后做出一些改进,甚至调整战略和业务。
数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据应用:
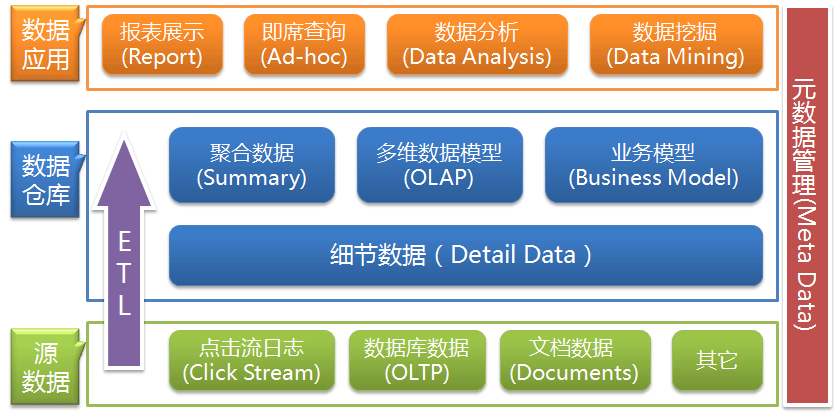
从图中可以看出数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自上而下流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer, 装载Load)的过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
下面主要简单介绍下数据仓库架构中的各个模块,当然这里所介绍的数据仓库主要是指网站数据仓库。
数据仓库的数据来源
对于网站数据仓库而言,点击流日志是一块主要的数据来源,它是网站分析的基础数据;当然网站的数据库数据也并不可少,其记录这网站运营的数据及各种用户操作的结果,对于分析网站Outcome这类数据更加精准;其他是网站内外部可能产生的文档及其它各类对于公司决策有用的数据。
数据仓库的数据存储
源数据通过ETL的日常任务调度导出,并经过转换后以特性的形式存入数据仓库。其实这个过程一直有很大的争议,就是到底数据仓库需不需要储存细节数据,一方的观点是数据仓库面向分析,所以只要存储特定需求的多维分析模型;另一方的观点是数据仓库先要建立和维护细节数据,再根据需求聚合和处理细节数据生成特定的分析模型。我比较偏向后面一个观点:数据仓库并不需要储存所有的原始数据,但数据仓库需要储存细节数据,并且导入的数据必须经过整理和转换使其面向主题。简单地解释下:
(1).为什么不需要所有原始数据?数据仓库面向分析处理,但是某些源数据对于分析而言没有价值或者其可能产生的价值远低于储存这些数据所需要的数据仓库的实现和性能上的成本。比如我们知道用户的省份、城市足够,至于用户究竟住哪里可能只是物流商关心的事,或者用户在博客的评论内容可能只是文本挖掘会有需要,但将这些冗长的评论文本存在数据仓库就得不偿失;
(2).为什么要存细节数据?细节数据是必需的,数据仓库的分析需求会时刻变化,而有了细节数据就可以做到以不变应万变,但如果我们只存储根据某些需求搭建起来的数据模型,那么显然对于频繁变动的需求会手足无措;
(3).为什么要面向主题?面向主题是数据仓库的第一特性,主要是指合理地组织数据以方面实现分析。对于源数据而言,其数据组织形式是多样的,像点击流的数据格式是未经优化的,前台数据库的数据是基于OLTP操作组织优化的,这些可能都不适合分析,而整理成面向主题的组织形式才是真正地利于分析的,比如将点击流日志整理成页面(Page)、访问(Visit或Session)、用户(Visitor)三个主题,这样可以明显提升分析的效率。
数据仓库基于维护细节数据的基础上在对数据进行处理,使其真正地能够应用于分析。主要包括三个方面:
数据的聚合
这里的聚合数据指的是基于特定需求的简单聚合(基于多维数据的聚合体现在多维数据模型中),简单聚合可以是网站的总Pageviews、Visits、Unique Visitors等汇总数据,也可以是Avg. time on page、Avg. time on site等平均数据,这些数据可以直接地展示于报表上。
多维数据模型
多维数据模型提供了多角度多层次的分析应用,比如基于时间维、地域维等构建的销售星形模型、雪花模型,可以实现在各时间维度和地域维度的交叉查询,以及基于时间维和地域维的细分。所以多维数据模型的应用一般都是基于联机分析处理(Online Analytical Process, OLAP)的,而面向特定需求群体的数据集市也会基于多维数据模型进行构建。
业务模型
这里的业务模型指的是基于某些数据分析和决策支持而建立起来的数据模型,比如我之前介绍过的用户评价模型、关联推荐模型、RFM分析模型等,或者是决策支持的线性规划模型、库存模型等;同时,数据挖掘中前期数据的处理也可以在这里完成。
数据仓库的数据应用
报表展示
报表几乎是每个数据仓库的必不可少的一类数据应用,将聚合数据和多维分析数据展示到报表,提供了最为简单和直观的数据。
即席查询
理论上数据仓库的所有数据(包括细节数据、聚合数据、多维数据和分析数据)都应该开放即席查询,即席查询提供了足够灵活的数据获取方式,用户可以根据自己的需要查询获取数据,并提供导出到Excel等外部文件的功能。
数据分析
数据分析大部分可以基于构建的业务模型展开,当然也可以使用聚合的数据进行趋势分析、比较分析、相关分析等,而多维数据模型提供了多维分析的数据基础;同时从细节数据中获取一些样本数据进行特定的分析也是较为常见的一种途径。
数据挖掘
数据挖掘用一些高级的算法可以让数据展现出各种令人惊讶的结果。数据挖掘可以基于数据仓库中已经构建起来的业务模型展开,但大多数时候数据挖掘会直接从细节数据上入手,而数据仓库为挖掘工具诸如SAS、SPSS等提供数据接口。
元数据管理
元数据(Meta Date),其实应该叫做解释性数据,即描述数据的数据。主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及ETL的任务运行状态。一般会通过元数据资料库(Metadata Repository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。
最后做个Ending,数据仓库本身既不生产数据也不消费数据,只是作为一个中间平台集成化地存储数据;数据仓库实现的难度在于整体架构的构建及ETL的设计,这也是日常管理维护中的重头;而数据仓库的真正价值体现在于基于其的数据应用上,如果没有有效的数据应用也就失去了构建数据仓库的意义。
本系统借助数据仓库的理论,主要采用spark技术生态框架进行离线计算,实时计算业务模块的开发,实现了包括用户session分析,页面单跳转转化率统计,热门商品离线统计,广告流量实时统计等业务模块。
接下来详细介绍整个系统的流程
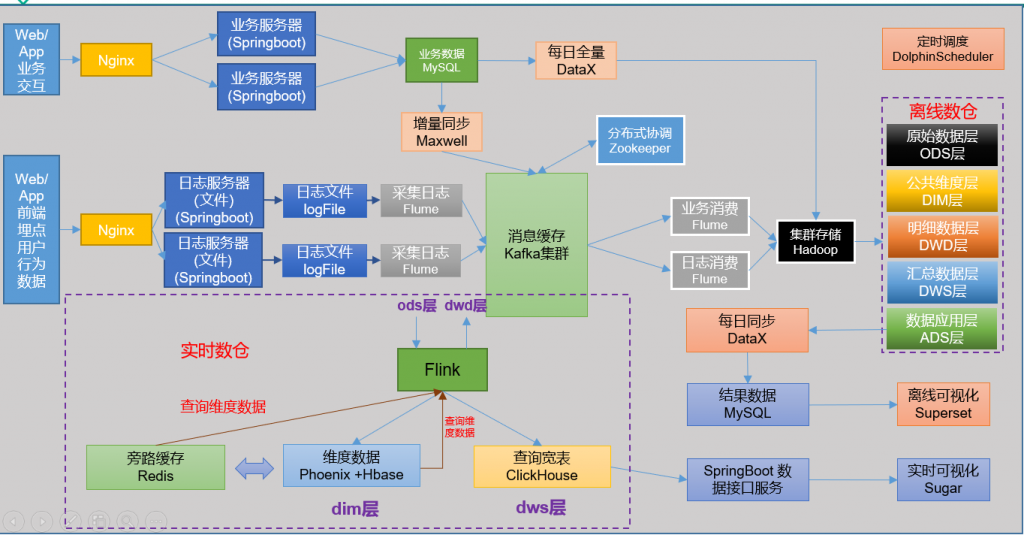
数据仓库不是最终目的,而是为了接下来的数据分析做好准备,这些准备包括对数据进行备份,清洗,聚合,统计等。
用户行为日志概述
用户行为日志的内容,主要包括用户的各项行为信息以及行为所处的环境信息。收集这些信息的主要目的是优化产品和为各项分析统计指标提供数据支撑。收集这些信息的手段通常为埋点。
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点等。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
用户行为日志内容
页面浏览记录
页面浏览记录,记录的是访客对页面的浏览行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及页面信息等。
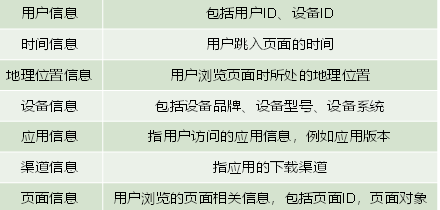
动作记录
动作记录,记录的是用户的业务操作行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息 及动作目标对象信息等。
曝光记录
曝光记录,记录的是曝光行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及曝光对象信息等。

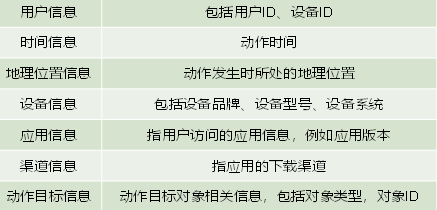
启动记录
启动记录,记录的是用户启动应用的行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、启动类型及开屏广告信息等。
错误记录
启动记录,记录的是用户在使用应用过程中的报错行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、以及可能与报错相关的页面信息、动作信息、曝光信息和动作信息。
用户行为日志格式
我们的日志结构大致可分为两类,一是页面日志,二是启动日志。
页面日志
页面日志,以页面浏览为单位,即一个页面浏览记录,生成一条页面埋点日志。一条完整的页面日志包含,一个页面浏览记录,若干个用户在该页面所做的动作记录,若干个该页面的曝光记录,以及一个在该页面发生的报错记录。除上述行为信息,页面日志还包含了这些行为所处的各种环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{
"common": { -- 环境信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"is_new": "1", -- 是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [{ -- 动作(事件)
"action_id": "favor_add", -- 动作id
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"ts": 1585744376605 -- 动作时间戳
}
],
"displays": [{ -- 曝光
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1, -- 出现顺序
"pos_id": 2 -- 曝光位置
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2,
"pos_id": 1
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3,
"pos_id": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4,
"pos_id": 2
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5,
"pos_id": 1
}
],
"page": { -- 页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err": { --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}
启动日志
启动日志以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"is_new": "1",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}
集群搭建
安装三台虚拟机分别命名为node01,node02,node03.
编写集群分发脚本xsync
xsync可以循环复制文件到所有节点的相同目录下
脚本实现
在/usr/bin目录下创建xsync文件,以便全局调用
编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in node01 node02 node03
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本xsync具有执行权限
chmod +x xsync
JDK准备
用XShell工具将JDK导入到node01的/opt/apps文件夹下面
之后解压重命名为jdk
配置JDK环境变量
新建/etc/profile.d/my_env.sh文件
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/apps/jdk
export PATH=$PATH:$JAVA_HOME/bin使得环境变量生效
source /etc/profile.d/my_env.sh
分发文件
xsync /opt/module/jdk
xsync /etc/profile.d/my_env.sh
分别在02和03执行source命令
模拟数据
将application.yml、commerce-mock-log-1.0.0.jar,path.json、logback.xml上传到node02的/opt/module/applog目录下
其中application.yml文件可以根据需求生成对应日期的用户行为日志。
我们根据自己的需求进行编写
# 外部配置打开
logging.config: "./logback.xml"
#业务日期,根据需求修改
mock.date: "2022-10-24"
#模拟数据发送模式
mock.type: "log"
#mock.type: "http"
#mock.type: "kafka"
#http模式下,发送的地址
mock.url: "http://localhost:8090/applog"
mock:
kafka-server: "node01:9092,node01:9092,node01:9092"
kafka-topic: "ODS_BASE_LOG"
#启动次数
mock.startup.count: 200
#设备最大值
mock.max.mid: 1000000
#会员最大值
mock.max.uid: 1000
#商品最大值
mock.max.sku-id: 35
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 20
#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"
#领取购物券概率
mock.if_get_coupon_rate: 75
#购物券最大id
mock.max.coupon-id: 3
#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
# 男女浏览商品比重(35sku)
mock.sku-weight.male: "10:10:10:10:10:10:10:5:5:5:5:5:10:10:10:10:12:12:12:12:12:5:5:5:5:3:3:3:3:3:3:3:3:10:10"
mock.sku-weight.female: "1:1:1:1:1:1:1:5:5:5:5:5:1:1:1:1:2:2:2:2:2:8:8:8:8:15:15:15:15:15:15:15:15:1:1"
path.json,该文件用来配置访问路径,根据需求,可以灵活配置用户点击路径。
[
{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":30 },
{"path":["home","search","good_list","good_detail","login","register","good_detail","cart","trade","payment"],"rate":20 },
{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5 },
{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5 },
{"path":["home","good_detail"],"rate":20 },
{"path":["home" ],"rate":10 }
]
logback配置文件
可配置日志生成路径,修改内容如下
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="/opt/module/applog/log" />
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.hnumi.commerce.mock.log.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="error" >
<appender-ref ref="console" />
<!-- <appender-ref ref="async-rollingFile" /> -->
</root>
</configuration>
生成日志
进入到/opt/module/applog路径,执行以下命令
java -jar commerce-mock-log-1.0.0.jar
在/opt/module/applog/log目录下查看生成日志
集群日志生成脚本
在usr/bin新建lg.sh脚本
vim lg.sh
#!/bin/bash
for i in node02 node03; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar commerce-mock-log-1.0.0.jar >/dev/null 2>&1 &"
done
修改脚本执行权限 chmod 777 lg.sh
将jar包及配置文件上传至node03的/opt/module/applog/路径
用户行为数据采集模块
集群所有进程查看脚本,在usr/bin目录下创建脚本xcall
vim xcall
#! /bin/bash
hosts=$(cat /etc/hosts | grep -v "^#" | awk '{print $2}')
for i in $hosts
do
echo --------- $i ----------
ssh $i "$*"
done
chmod 777 xcall
启动:xcall jps,能够查看所有节点的命令回调。
Hadoop安装
集群部署规划
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| node01 | node02 | node03 | |
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
用xftp工具将hadoop-3.1.3.tar.gz导入到opt目录下面的apps文件夹下面
解压,修改名称为hadoop,然后添加环境变量
在/etc/profile.d/my_env.sh文件中添加
#HADOOP_HOME
export HADOOP_HOME=/opt/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出,分发文件
xsync /etc/profile.d/my_env.sh
之后每个节点source一下。
配置集群
core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apps/hadoop/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--在<configuration>中间添加一下内容-->
<property><!--namenode节点 元数据存储目录【必须配置】-->
<name>dfs.namenode.name.dir</name>
<value>file:/opt/apps/hadoop/dfs/name</value>
</property>
<property><!--datanode 真正的数据存储目录【必须配置】-->
<name>dfs.datanode.data.dir</name>
<value>file:/opt/apps/hadoop/dfs/data</value>
</property>
<property><!--指定DataNode存储block的副本数量,不大于DataNode的个数就行,默认为3【必须】-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property><!--指定SecondaryNamenode的工作目录【必须配置】-->
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/opt/apps/hadoop/dfs/namesecondary</value>
</property>
<property><!--指定SecondaryNamenode的http协议访问地址【必须配置】-->
<name>dfs.namenode.secondary.http-address</name>
<value>node03:9868</value>
</property>
<property><!--指定SecondaryNamenode的https协议访问地址:【可以不进行配置】-->
<name>dfs.namenode.secondary.https-address</name>
<value>node03:9869</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!--在<configuration></configuration>中间添加一下内容-->
<property>
<!--Reducer获取数据的方式【必须配置】-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--Reducer获取数据的方式中shuffle过程对应的类,可以自定义,【可以不配置】,这是默认的-->
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--ResourceManager主机名,配置后其他的address就不用配置了,除非需要自定义端口【必须配置】-->
<name>yarn.resourcemanager.hostname</name>
<value>node02</value>
</property>
<property>
<!--NodeManager节点的内存大小,单位为MB【必须配置】-->
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<!--NodeManager节点硬件的自动探测,主要为修正CPU个数,开启后不影响前面内存的配置-->
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>
<!-- 日志聚集功能【暂时不需要配置】 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 【暂时不需要配置】-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
在workers中只保留
node01
node02
node03文件分发
xsync /opt/apps/hadoop
格式化
hdfs namenode -format
启动
start-dfs.sh
start-yarn.sh
网页端访问
192.168.100.101:9870
zookper
集群规划
| 服务器node01 | 服务器node02 | 服务器node03 | |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
解压Zookeeper安装包到/opt/apps/目录下,修改名称
创建zkData,zkData目录下创建一个myid的文件,内容node01对应写1,写到3
conf这个目录下的zoo_sample.cfg为zoo.cfg
修改
dataDir=/opt/apps/zookeeper/zkData
添加
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
同步
xsync zookeeper
启动
注意要分别启动
bin/zkServer.sh start
查看状态
bin/zkServer.sh status
ZK集群启动停止脚本
zk.sh
#!/bin/bash
case $1 in
"start"){
for i in node01 node02 node03
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh start"
done
};;
"stop"){
for i in node01 node02 node03
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in node01 node02 node03
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/apps/zookeeper/bin/zkServer.sh status"
done
};;
esac
添加权限
chmod 777 zk.sh
启动
zk.sh start
Kafka安装
集群规划
| node01 | node02 | node03 |
| zk | zk | zk |
| kafka | kafka | kafka |
集群部署
官方下载地址:http://kafka.apache.org/downloads.html
解压安装包,修改名称
修改配置文件
cd config/
vim server.properties
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/apps/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=node01:2181,node02:2181,node03:2181/kafka
分发
xsync kafka/
分别在node02和node03上修改配置文件/opt/apps/kafka/config/server.properties中的broker.id=1、broker.id=2
配置环境变量
在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
#KAFKA_HOME
export KAFKA_HOME=/opt/apps/kafka
export PATH=$PATH:$KAFKA_HOME/bin
分发环境变量文件到其他节点
启动集群
先启动Zookeeper集群,然后启动Kafka。
依次在node01、node02、node03节点上启动Kafka。
启动脚本
kf.sh
#! /bin/bash
case $1 in
"start"){
for i in node01 node02 node03
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/apps/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in node01 node02 node03
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/apps/kafka/bin/kafka-server-stop.sh "
done
};;
esac
启动
kf.sh start
Flume安装
安装部署
将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/apps目录下
解压apache-flume-1.9.0-bin.tar.gz到/opt/apps/目录下,改名
将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
修改conf目录下的log4j.properties配置文件,配置日志文件路径
flume.log.dir=/opt/apps/flume/logs
配置环境变量
#Flume
export FLUME_HOME=/opt/apps/flume
export PATH=$PATH:$FLUME_HOME/bin
分发目录
xsync /opt/apps/flume
分发环境变量设置
xsync /etc/profile.d/my_env.sh
日志采集Flume配置概述
按照规划,需要采集的用户行为日志文件分布在node01,node02两台日志服务器,故需要在node01,node02两台节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
此处可选择TaildirSource和KafkaChannel,并配置日志校验拦截器。
选择TailDirSource和KafkaChannel的原因如下:
TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。
KafkaChannel
采用Kafka Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:
日志采集Flume配置实操
创建Flume配置文件
在node01节点的Flume的job目录下创建file_to_kafka.conf
配置文件内容如下
#定义组件
a1.sources = r1
a1.channels = c1
#配置source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/apps/applog/log/app.*
a1.sources.r1.positionFile = /opt/apps/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.ETLInterceptor$Builder
#配置channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = node01:9092,node02:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#组装
a1.sources.r1.channels = c13)编写Flume拦截器
(1)创建Maven工程flume-interceptor
(2)创建包:com.atguigu.gmall.flume.interceptor
(3)在pom.xml文件中添加如下配置
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
(4)在com.atguigu.gmall.flume.utils包下创建JSONUtil类
package com.atguigu.gmall.flume.utils;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.JSONException;
public class JSONUtil {
/*
* 通过异常判断是否是json字符串
* 是:返回true 不是:返回false
* */
public static boolean isJSONValidate(String log){
try {
JSONObject.parseObject(log);
return true;
}catch (JSONException e){
return false;
}
}
}
(5)在com.atguigu.gmall.flume.interceptor包下创建ETLInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.atguigu.gmall.flume.utils.JSONUtil;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取body当中的数据并转成字符串
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
//2、判断字符串是否是一个合法的json,是:返回当前event;不是:返回null
if (JSONUtil.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}
(6)打包
(7)需要先将打好的包放入到node01的/opt/apps/flume/lib文件夹下面。
日志采集Flume测试
启动Zookeeper、Kafka集群
启动hadoop102的日志采集Flume
bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
启动一个Kafka的Console-Consumer
bin/kafka-console-consumer.sh –bootstrap-server node01:9092 –topic topic_log
生成模拟数据
lg.sh
观察Kafka消费者是否能消费到数据
日志采集Flume启停脚本
分发日志采集Flume配置文件和拦截器
若上述测试通过,需将node01节点的Flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。
scp -r job node02:/opt/apps/flume/
scp lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar node02:/opt/apps/flume/lib/
方便起见,此处编写一个日志采集Flume进程的启停脚本f1.sh
#!/bin/bash
case $1 in
"start"){
for i in node01 node02
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/apps/flume/bin/flume-ng agent -n a1 -c /opt/apps/flume/conf/ -f /opt/apps/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in node01 node02
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
增加脚本权限
启动
f1.sh start
接下来是对业务数据进行采集。
电商业务简介
电商业务流程
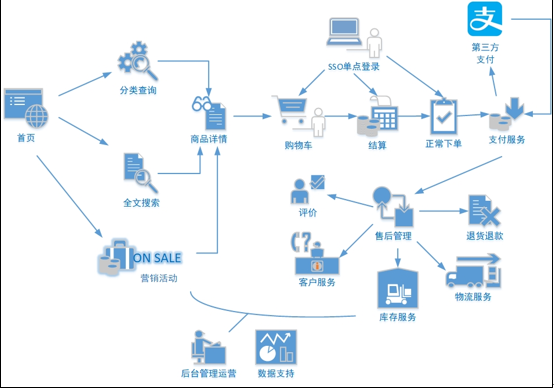
电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品无疑都是存储在后台的管理系统中的。
当用户寻找到自己中意的商品,可能会想要购买,将商品添加到购物车后发现需要登录,登录后对商品进行结算,这时候购物车的管理和商品订单信息的生成都会对业务数据库产生影响,会生成相应的订单数据和支付数据。
订单正式生成之后,还会对订单进行跟踪处理,直到订单全部完成。
电商的主要业务流程包括用户前台浏览商品时的商品详情的管理,用户商品加入购物车进行支付时用户个人中心&支付服务的管理,用户支付完成后订单后台服务的管理,这些流程涉及到了十几个甚至几十个业务数据表,甚至更多。
SKU和SPU
SKU = Stock Keeping Unit(库存量基本单位)。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhoneX手机就是SPU。一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
业务数据介绍
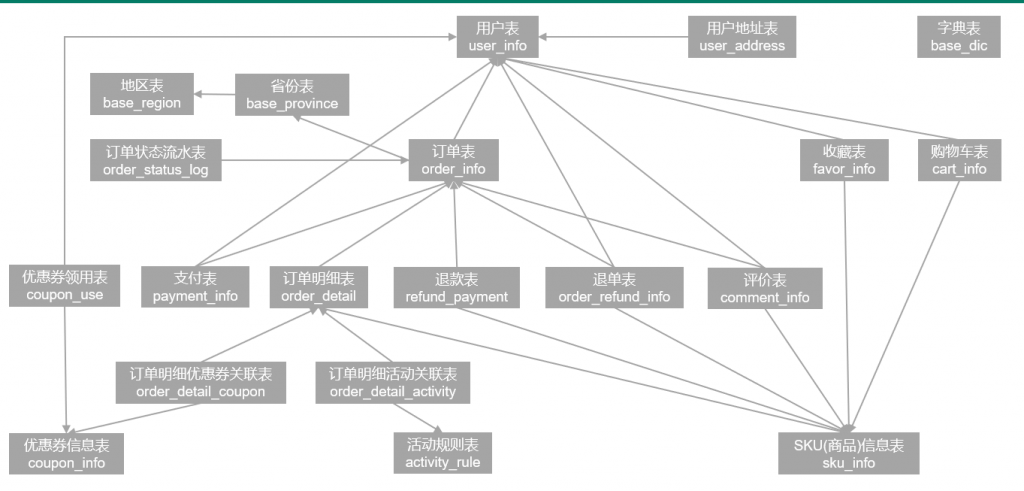
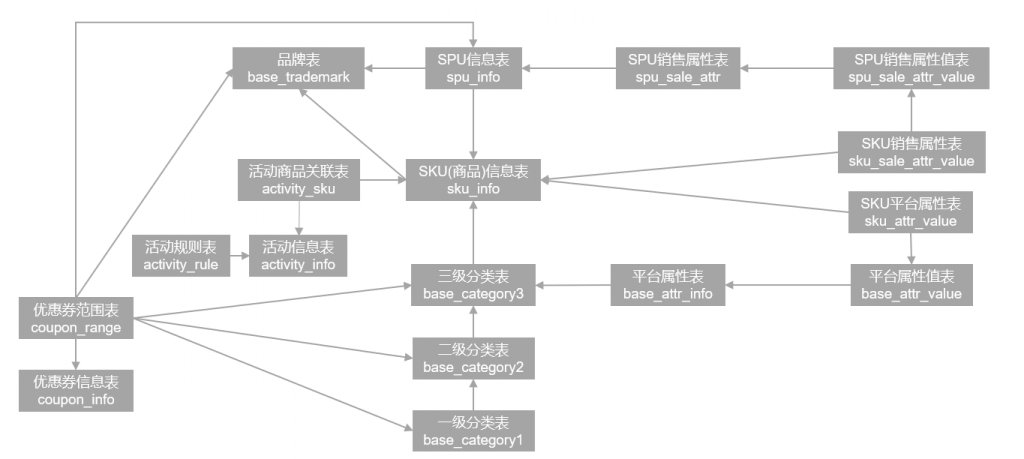
电商系统表结构
以下为本电商数仓系统涉及到的业务数据表结构关系。这34个表以订单表、用户表、SKU商品表、活动表和优惠券表为中心,延伸出了优惠券领用表、支付流水表、活动订单表、订单详情表、订单状态表、商品评论表、编码字典表退单表、SPU商品表等,用户表提供用户的详细信息,支付流水表提供该订单的支付详情,订单详情表提供订单的商品数量等情况,商品表给订单详情表提供商品的详细信息。本次讲解以此34个表为例,实际项目中,业务数据库中表格远远不止这些。
活动信息表(activity_info)
| 字段名 | 字段说明 |
| id | 活动id |
| activity_name | 活动名称 |
| activity_type | 活动类型(1:满减,2:折扣) |
| activity_desc | 活动描述 |
| start_time | 开始时间 |
| end_time | 结束时间 |
| create_time | 创建时间 |
2.1.2 活动规则表(activity_rule)
| id | 编号 |
| activity_id | 活动ID |
| activity_type | 活动类型 |
| condition_amount | 满减金额 |
| condition_num | 满减件数 |
| benefit_amount | 优惠金额 |
| benefit_discount | 优惠折扣 |
| benefit_level | 优惠级别 |
2.1.3 活动商品关联表(activity_sku)
| 字段名 | 字段说明 |
| id | 编号 |
| activity_id | 活动id |
| sku_id | sku_id |
| create_time | 创建时间 |
2.1.4 平台属性表(base_attr_info)
| 字段名 | 字段说明 |
| id | 编号 |
| attr_name | 属性名称 |
| category_id | 分类id |
| category_level | 分类层级 |
2.1.5 平台属性值表(base_attr_value)
| 字段名 | 字段说明 |
| id | 编号 |
| value_name | 属性值名称 |
| attr_id | 属性id |
2.1.6 一级分类表(base_category1)
| 字段名 | 字段说明 |
| id | 编号 |
| name | 分类名称 |
2.1.7 二级分类表(base_category2)
| 字段名 | 字段说明 |
| id | 编号 |
| name | 二级分类名称 |
| category1_id | 一级分类编号 |
2.1.8 三级分类表(base_category3)
| 字段名 | 字段说明 |
| id | 编号 |
| name | 三级分类名称 |
| category2_id | 二级分类编号 |
2.1.9 字典表(base_dic)
| 字段名 | 字段说明 |
| dic_code | 编号 |
| dic_name | 编码名称 |
| parent_code | 父编号 |
| create_time | 创建日期 |
| operate_time | 修改日期 |
2.1.10 省份表(base_province)
| 字段名 | 字段说明 |
| id | id |
| name | 省名称 |
| region_id | 大区id |
| area_code | 行政区位码 |
| iso_code | 国际编码 |
| iso_3166_2 | ISO3166编码 |
2.1.11 地区表(base_region)
| 字段名 | 字段说明 |
| id | 大区id |
| region_name | 大区名称 |
2.1.12 品牌表(base_trademark)
| 字段名 | 字段说明 |
| id | 编号 |
| tm_name | 属性值 |
| logo_url | 品牌logo的图片路径 |
2.1.13 购物车表(cart_info)
| 字段名 | 字段说明 |
| id | 编号 |
| user_id | 用户id |
| sku_id | skuid |
| cart_price | 放入购物车时价格 |
| sku_num | 数量 |
| img_url | 图片文件 |
| sku_name | sku名称 (冗余) |
| is_checked | 是否已经下单 |
| create_time | 创建时间 |
| operate_time | 修改时间 |
| is_ordered | 是否已经下单 |
| order_time | 下单时间 |
| source_type | 来源类型 |
| source_id | 来源编号 |
2.1.14 评价表(comment_info)
| 字段名 | 字段说明 |
| id | 编号 |
| user_id | 用户id |
| nick_name | 用户昵称 |
| head_img | 图片 |
| sku_id | 商品sku_id |
| spu_id | 商品spu_id |
| order_id | 订单编号 |
| appraise | 评价 1 好评 2 中评 3 差评 |
| comment_txt | 评价内容 |
| create_time | 创建时间 |
| operate_time | 修改时间 |
2.1.15 优惠券信息表(coupon_info)
| 字段名 | 字段说明 |
| id | 购物券编号 |
| coupon_name | 购物券名称 |
| coupon_type | 购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券 |
| condition_amount | 满额数(3) |
| condition_num | 满件数(4) |
| activity_id | 活动编号 |
| benefit_amount | 减金额(1 3) |
| benefit_discount | 折扣(2 4) |
| create_time | 创建时间 |
| range_type | 范围类型 1、商品(spuid) 2、品类(三级分类id) 3、品牌 |
| limit_num | 最多领用次数 |
| taken_count | 已领用次数 |
| start_time | 可以领取的开始日期 |
| end_time | 可以领取的结束日期 |
| operate_time | 修改时间 |
| expire_time | 过期时间 |
| range_desc | 范围描述 |
2.1.16 优惠券优惠范围表(coupon_range)
| 字段名 | 字段说明 |
| id | 购物券编号 |
| coupon_id | 优惠券id |
| range_type | 范围类型 1、商品(spuid) 2、品类(三级分类id) 3、品牌 |
| range_id | 范围id |
2.1.17 优惠券领用表(coupon_use)
| 字段名 | 字段说明 |
| id | 编号 |
| coupon_id | 购物券id |
| user_id | 用户id |
| order_id | 订单id |
| coupon_status | 购物券状态(1:未使用 2:已使用) |
| get_time | 获取时间 |
| using_time | 使用时间 |
| used_time | 支付时间 |
| expire_time | 过期时间 |
2.1.18 收藏表(favor_info)
| 字段名 | 字段说明 |
| id | 编号 |
| user_id | 用户id |
| sku_id | skuid |
| spu_id | 商品id |
| is_cancel | 是否已取消 0 正常 1 已取消 |
| create_time | 创建时间 |
| cancel_time | 修改时间 |
2.1.19 订单明细表(order_detail)
| 字段名 | 字段说明 |
| id | 编号 |
| order_id | 订单编号 |
| sku_id | sku_id |
| sku_name | sku名称(冗余) |
| img_url | 图片名称(冗余) |
| order_price | 购买价格(下单时sku价格) |
| sku_num | 购买个数 |
| create_time | 创建时间 |
| source_type | 来源类型 |
| source_id | 来源编号 |
| split_total_amount | 分摊总金额 |
| split_activity_amount | 分摊活动减免金额 |
| split_coupon_amount | 分摊优惠券减免金额 |
2.1.20 订单明细活动关联表(order_detail_activity)
| 字段名 | 字段说明 |
| id | 编号 |
| order_id | 订单id |
| order_detail_id | 订单明细id |
| activity_id | 活动id |
| activity_rule_id | 活动规则 |
| sku_id | skuid |
| create_time | 获取时间 |
2.1.21 订单明细优惠券关联表(order_detail_coupon)
| 字段名 | 字段说明 |
| id | 编号 |
| order_id | 订单id |
| order_detail_id | 订单明细id |
| coupon_id | 购物券id |
| coupon_use_id | 购物券领用id |
| sku_id | skuid |
| create_time | 获取时间 |
2.1.22 订单表(order_info)
| 字段名 | 字段说明 |
| id | 编号 |
| consignee | 收货人 |
| consignee_tel | 收件人电话 |
| total_amount | 总金额 |
| order_status | 订单状态 |
| user_id | 用户id |
| payment_way | 付款方式 |
| delivery_address | 送货地址 |
| order_comment | 订单备注 |
| out_trade_no | 订单交易编号(第三方支付用) |
| trade_body | 订单描述(第三方支付用) |
| create_time | 创建时间 |
| operate_time | 操作时间 |
| expire_time | 失效时间 |
| process_status | 进度状态 |
| tracking_no | 物流单编号 |
| parent_order_id | 父订单编号 |
| img_url | 图片路径 |
| province_id | 地区 |
| activity_reduce_amount | 促销金额 |
| coupon_reduce_amount | 优惠金额 |
| original_total_amount | 原价金额 |
| feight_fee | 运费 |
| feight_fee_reduce | 运费减免 |
| refundable_time | 可退款日期(签收后30天) |
2.1.23 退单表(order_refund_info)
| 字段名 | 字段说明 |
| id | 编号 |
| user_id | 用户id |
| order_id | 订单id |
| sku_id | skuid |
| refund_type | 退款类型 |
| refund_num | 退货件数 |
| refund_amount | 退款金额 |
| refund_reason_type | 原因类型 |
| refund_reason_txt | 原因内容 |
| refund_status | 退款状态(0:待审批 1:已退款) |
| create_time | 创建时间 |
2.1.24 订单状态流水表(order_status_log)
| 字段名 | 字段说明 |
| id | 编号 |
| order_id | 订单编号 |
| order_status | 订单状态 |
| operate_time | 操作时间 |
2.1.25 支付表(payment_info)
| 字段名 | 字段说明 |
| id | 编号 |
| out_trade_no | 对外业务编号 |
| order_id | 订单编号 |
| user_id | 用户id |
| payment_type | 支付类型(微信 支付宝) |
| trade_no | 交易编号 |
| total_amount | 支付金额 |
| subject | 交易内容 |
| payment_status | 支付状态 |
| create_time | 创建时间 |
| callback_time | 回调时间 |
| callback_content | 回调信息 |
2.1.26 退款表(refund_payment)
| 字段名 | 字段说明 |
| id | 编号 |
| out_trade_no | 对外业务编号 |
| order_id | 订单编号 |
| sku_id | 商品sku_id |
| payment_type | 支付类型(微信 支付宝) |
| trade_no | 交易编号 |
| total_amount | 退款金额 |
| subject | 交易内容 |
| refund_status | 退款状态 |
| create_time | 创建时间 |
| callback_time | 回调时间 |
| callback_content | 回调信息 |
2.1.27 SKU平台属性表(sku_attr_value)
| 字段名 | 字段说明 |
| id | 编号 |
| attr_id | 属性id(冗余) |
| value_id | 属性值id |
| sku_id | skuid |
| attr_name | 属性名称 |
| value_name | 属性值名称 |
2.1.28 SKU信息表(sku_info)
| 字段名 | 字段说明 |
| id | 库存id(itemID) |
| spu_id | 商品id |
| price | 价格 |
| sku_name | sku名称 |
| sku_desc | 商品规格描述 |
| weight | 重量 |
| tm_id | 品牌(冗余) |
| category3_id | 三级分类id(冗余) |
| sku_default_img | 默认显示图片(冗余) |
| is_sale | 是否销售(1:是 0:否) |
| create_time | 创建时间 |
2.1.29 SKU销售属性表(sku_sale_attr_value)
| 字段名 | 字段说明 |
| id | id |
| sku_id | 库存单元id |
| spu_id | spu_id(冗余) |
| sale_attr_value_id | 销售属性值id |
| sale_attr_id | 销售属性id |
| sale_attr_name | 销售属性值名称 |
| sale_attr_value_name | 销售属性值名称 |
2.1.30 SPU信息表(spu_info)
| 字段名 | 字段说明 |
| id | 商品id |
| spu_name | 商品名称 |
| description | 商品描述(后台简述) |
| category3_id | 三级分类id |
| tm_id | 品牌id |
2.1.31 SPU销售属性表(spu_sale_attr)
| 字段名 | 字段说明 |
| id | 编号(业务中无关联) |
| spu_id | 商品id |
| base_sale_attr_id | 销售属性id |
| sale_attr_name | 销售属性名称(冗余) |
2.1.32 SPU销售属性值表(spu_sale_attr_value)
| 字段名 | 字段说明 |
| id | 销售属性值编号 |
| spu_id | 商品id |
| base_sale_attr_id | 销售属性id |
| sale_attr_value_name | 销售属性值名称 |
| sale_attr_name | 销售属性名称(冗余) |
2.1.33 用户地址表(user_address)
| 字段名 | 字段说明 |
| id | 编号 |
| user_id | 用户id |
| province_id | 省份id |
| user_address | 用户地址 |
| consignee | 收件人 |
| phone_num | 联系方式 |
| is_default | 是否是默认 |
2.1.34 用户信息表(user_info)
| 字段名 | 字段说明 |
| id | 编号 |
| login_name | 用户名称 |
| nick_name | 用户昵称 |
| passwd | 用户密码 |
| name | 用户姓名 |
| phone_num | 手机号 |
| 邮箱 | |
| head_img | 头像 |
| user_level | 用户级别 |
| birthday | 用户生日 |
| gender | 性别 M男,F女 |
| create_time | 创建时间 |
| operate_time | 修改时间 |
| status | 状态 |
MySQL安装
卸载自带的Mysql-libs(如果之前安装过MySQL,要全都卸载掉)
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e –nodeps
安装MySQL依赖
rpm -ivh 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm
rpm -ivh 02_mysql-community-libs-5.7.16-1.el7.x86_64.rpm
rpm -ivh 03_mysql-community-libs-compat-5.7.16-1.el7.x86_64.rpm
安装mysql-client
rpm -ivh 04_mysql-community-client-5.7.16-1.el7.x86_64.rpm
安装mysql-server
rpm -ivh 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm
启动MySQL
systemctl start mysqld
查看MySQL密码
cat /var/log/mysqld.log | grep password
配置MySQL
用刚刚查到的密码进入MySQL(如果报错,给密码加单引号)
mysql -uroot -p’password’
更改MySQL密码策略
mysql> set global validate_password_length=4;
mysql> set global validate_password_policy=0;
设置简单好记的密码
mysql> set password=password(“123456”);
之后利用navicat导入数据库脚本文件gmall.sql
生成业务数据
在node01的/opt/apps/目录下创建db_log文件夹
把gmall2020-mock-db-2021-11-14.jar和application.properties上传到node01的/opt/apps/db_log路径上。
根据需求修改application.properties相关配置
logging.level.root=info
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://node01:3306/gmall?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=123456
logging.pattern.console=%m%n
mybatis-plus.global-config.db-config.field-strategy=not_null
#业务日期
mock.date=2020-06-14
#是否重置 注意:第一次执行必须设置为1,后续不需要重置不用设置为1
mock.clear=1
#是否重置用户 注意:第一次执行必须设置为1,后续不需要重置不用设置为1
mock.clear.user=1
#生成新用户数量
mock.user.count=100
#男性比例
mock.user.male-rate=20
#用户数据变化概率
mock.user.update-rate:20
#收藏取消比例
mock.favor.cancel-rate=10
#收藏数量
mock.favor.count=100
#每个用户添加购物车的概率
mock.cart.user-rate=50
#每次每个用户最多添加多少种商品进购物车
mock.cart.max-sku-count=8
#每个商品最多买几个
mock.cart.max-sku-num=3
#购物车来源 用户查询,商品推广,智能推荐, 促销活动
mock.cart.source-type-rate=60:20:10:10
#用户下单比例
mock.order.user-rate=50
#用户从购物中购买商品比例
mock.order.sku-rate=50
#是否参加活动
mock.order.join-activity=1
#是否使用购物券
mock.order.use-coupon=1
#购物券领取人数
mock.coupon.user-count=100
#支付比例
mock.payment.rate=70
#支付方式 支付宝:微信 :银联
mock.payment.payment-type=30:60:10
#评价比例 好:中:差:自动
mock.comment.appraise-rate=30:10:10:50
#退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他
mock.refund.reason-rate=30:10:20:5:15:5:5
业务数据采集模块
Maxwell简介
Maxwell概述
Maxwell 是由美国Zendesk公司开源,用Java编写的MySQL变更数据抓取软件。它会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变更数据以 JSON 格式发送给 Kafka、Kinesi等流数据处理平台。官网地址:http://maxwells-daemon.io/
Maxwell输出数据格式

Maxwell原理
Maxwell的工作原理是实时读取MySQL数据库的二进制日志(Binlog),从中获取变更数据,再将变更数据以JSON格式发送至Kafka等流处理平台。
MySQL二进制日志
二进制日志(Binlog)是MySQL服务端非常重要的一种日志,它会保存MySQL数据库的所有数据变更记录。Binlog的主要作用包括主从复制和数据恢复。Maxwell的工作原理和主从复制密切相关。
MySQL主从复制
MySQL的主从复制,就是用来建立一个和主数据库完全一样的数据库环境,这个数据库称为从数据库。
主从复制的应用场景如下:
(1)做数据库的热备:主数据库服务器故障后,可切换到从数据库继续工作。
(2)读写分离:主数据库只负责业务数据的写入操作,而多个从数据库只负责业务数据的查询工作,在读多写少场景下,可以提高数据库工作效率。
主从复制的工作原理如下:
(1)Master主库将数据变更记录,写到二进制日志(binary log)中
(2)Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log)
(3)Slave从库读取并回放中继日志中的事件,将改变的数据同步到自己的数据库。
很简单,就是将自己伪装成slave,并遵循MySQL主从复制的协议,从master同步数据。
下载安装包
(1)地址:https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
注:Maxwell-1.30.0及以上版本不再支持JDK1.8。
(2)将安装包上传到node01节点的/opt/apps目录
将安装包解压至/opt/apps
tar -zxvf maxwell-1.29.2.tar.gz -C /opt/apps/
修改名称
mv maxwell-1.29.2/ maxwell
配置MySQL
启用MySQL Binlog
MySQL服务器的Binlog默认是未开启的,如需进行同步,需要先进行开启。
修改MySQL配置文件/etc/my.cnf
sudo vim /etc/my.cnf
增加如下配置
[mysqld]
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall
注:MySQL Binlog模式
Statement-based:基于语句,Binlog会记录所有写操作的SQL语句,包括insert、update、delete等。
优点: 节省空间
缺点: 有可能造成数据不一致,例如insert语句中包含now()函数。
Row-based:基于行,Binlog会记录每次写操作后被操作行记录的变化。
优点:保持数据的绝对一致性。
缺点:占用较大空间。
mixed:混合模式,默认是Statement-based,如果SQL语句可能导致数据不一致,就自动切换到Row-based。
Maxwell要求Binlog采用Row-based模式。
重启MySQL服务
systemctl restart mysqld
创建Maxwell所需数据库和用户
Maxwell需要在MySQL中存储其运行过程中的所需的一些数据,包括binlog同步的断点位置(Maxwell支持断点续传)等等,故需要在MySQL为Maxwell创建数据库及用户。
创建数据库
msyql> CREATE DATABASE maxwell;
调整MySQL数据库密码级别
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
创建Maxwell用户并赋予其必要权限
mysql> CREATE USER ‘maxwell’@’%’ IDENTIFIED BY ‘maxwell’;
mysql> GRANT ALL ON maxwell.* TO ‘maxwell’@’%’;
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO ‘maxwell’@’%’;
配置Maxwell
修改Maxwell配置文件名称
cd /opt/apps/maxwell
cp config.properties.example config.properties
修改Maxwell配置文件
vim config.properties
log_level=info
producer=kafka
kafka.bootstrap.servers=node01:9092,node02:9092
#kafka topic配置
kafka_topic=topic_db
# mysql login info
host=node01
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
Maxwell使用
启动Kafka集群
若Maxwell发送数据的目的地为Kafka集群,则需要先确保Kafka集群为启动状态。
Maxwell启停
启动Maxwell
/opt/apps/maxwell/bin/maxwell –config /opt/apps/maxwell/config.properties –daemon
停止Maxwell
ps -ef | grep maxwell | grep -v grep | grep maxwell | awk ‘{print $2}’ | xargs kill -9
Maxwell启停脚本
创建并编辑Maxwell启停脚本
vim mxw.sh
脚本内容如下
#!/bin/bash
MAXWELL_HOME=/opt/apps/maxwell
status_maxwell(){
result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`
return $result
}
start_maxwell(){
status_maxwell
if [[ $? -lt 1 ]]; then
echo "启动Maxwell"
$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemon
else
echo "Maxwell正在运行"
fi
}
stop_maxwell(){
status_maxwell
if [[ $? -gt 0 ]]; then
echo "停止Maxwell"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
else
echo "Maxwell未在运行"
fi
}
case $1 in
start )
start_maxwell
;;
stop )
stop_maxwell
;;
restart )
stop_maxwell
start_maxwell
;;
esac增量数据同步
启动Kafka消费者
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --topic maxwell模拟生成数据
java -jar gmall2020-mock-db-2021-01-22.jar
历史数据全量同步
上一节,我们已经实现了使用Maxwell实时增量同步MySQL变更数据的功能。但有时只有增量数据是不够的,我们可能需要使用到MySQL数据库中从历史至今的一个完整的数据集。这就需要我们在进行增量同步之前,先进行一次历史数据的全量同步。这样就能保证得到一个完整的数据集。
Maxwell-bootstrap
/opt/apps/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/apps/maxwell/config.properties实时数仓同步数据
实时数仓由Flink源源不断从Kafka当中读数据计算,所以不需要手动同步数据到实时数仓。
日志消费Flume配置概述
按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往HDFS不同天的路径。
此处选择KafkaSource、FileChannel、HDFSSink。
创建Flume配置文件
在node03节点的Flume的job目录下创建kafka_to_hdfs_log.conf,配置文件内容如下
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder
#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/apps/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/apps/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
编写Flume拦截器
在com.atguigu.gmall.flume.interceptor包下创建TimestampInterceptor类
package com.atguigu.gmall.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;
public class TimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//1、获取header和body的数据
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
//2、将body的数据类型转成jsonObject类型(方便获取数据)
JSONObject jsonObject = JSONObject.parseObject(log);
//3、header中timestamp时间字段替换成日志生成的时间戳(解决数据漂移问题)
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
之后重新打包日志消费Flume启停脚本
f2.sh
#!/bin/bash
case $1 in
"start")
echo " --------启动 node03日志数据flume-------"
ssh node03"nohup /opt/apps/flume/bin/flume-ng agent -n a1 -c /opt/apps/flume/conf -f /opt/apps/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 node03日志数据flume-------"
ssh node03"ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
业务数据同步
数据同步策略概述
业务数据是数据仓库的重要数据来源,我们需要每日定时从业务数据库中抽取数据,传输到数据仓库中,之后再对数据进行分析统计。
为保证统计结果的正确性,需要保证数据仓库中的数据与业务数据库是同步的,离线数仓的计算周期通常为天,所以数据同步周期也通常为天,即每天同步一次即可。
数据的同步策略有全量同步和增量同步。
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
数据同步策略选择
两种策略都能保证数据仓库和业务数据库的数据同步,那应该如何选择呢?下面对两种策略进行简要对比。
| 同步策略 | 优点 | 缺点 |
| 全量同步 | 逻辑简单 | 在某些情况下效率较低。例如某张表数据量较大,但是每天数据的变化比例很低,若对其采用每日全量同步,则会重复同步和存储大量相同的数据。 |
| 增量同步 | 效率高,无需同步和存储重复数据 | 逻辑复杂,需要将每日的新增及变化数据同原来的数据进行整合,才能使用 |
根据上述对比,可以得出以下结论: 通常情况,业务表数据量比较大,优先考虑增量,数据量比较小,优先考虑全量;具体选择由数仓模型决定
数据同步工具概述
数据同步工具种类繁多,大致可分为两类,一类是以DataX、Sqoop为代表的基于Select查询的离线、批量同步工具,另一类是以Maxwell、Canal为代表的基于数据库数据变更日志(例如MySQL的binlog,其会实时记录所有的insert、update以及delete操作)的实时流式同步工具。
全量同步通常使用DataX、Sqoop等基于查询的离线同步工具。而增量同步既可以使用DataX、Sqoop等工具,也可使用Maxwell、Canal等工具,下面对增量同步不同方案进行简要对比。
| 增量同步方案 | DataX/Sqoop | Maxwell/Canal |
| 对数据库的要求 | 原理是基于查询,故若想通过select查询获取新增及变化数据,就要求数据表中存在create_time、update_time等字段,然后根据这些字段获取变更数据。 | 要求数据库记录变更操作,例如MySQL需开启binlog。 |
| 数据的中间状态 | 由于是离线批量同步,故若一条数据在一天中变化多次,该方案只能获取最后一个状态,中间状态无法获取。 | 由于是实时获取所有的数据变更操作,所以可以获取变更数据的所有中间状态。 |
本项目中,全量同步采用DataX,增量同步采用Maxwell。
全量同步
DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
源码地址:https://github.com/alibaba/DataX
DataX支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图。
| 类型 | 数据源 | Reader(读) | Writer(写) |
| RDBMS 关系型数据库 | MySQL | √ | √ |
| Oracle | √ | √ | |
| OceanBase | √ | √ | |
| SQLServer | √ | √ | |
| PostgreSQL | √ | √ | |
| DRDS | √ | √ | |
| 通用RDBMS | √ | √ | |
| 阿里云数仓数据存储 | ODPS | √ | √ |
| ADS | √ | ||
| OSS | √ | √ | |
| OCS | √ | √ | |
| NoSQL数据存储 | OTS | √ | √ |
| Hbase0.94 | √ | √ | |
| Hbase1.1 | √ | √ | |
| Phoenix4.x | √ | √ | |
| Phoenix5.x | √ | √ | |
| MongoDB | √ | √ | |
| Hive | √ | √ | |
| Cassandra | √ | √ | |
| 无结构化数据存储 | TxtFile | √ | √ |
| FTP | √ | √ | |
| HDFS | √ | √ | |
| Elasticsearch | √ | ||
| 时间序列数据库 | OpenTSDB | √ | |
| TSDB | √ | √ |
DataX架构原理
DataX设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
DataX框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
DataX运行流程
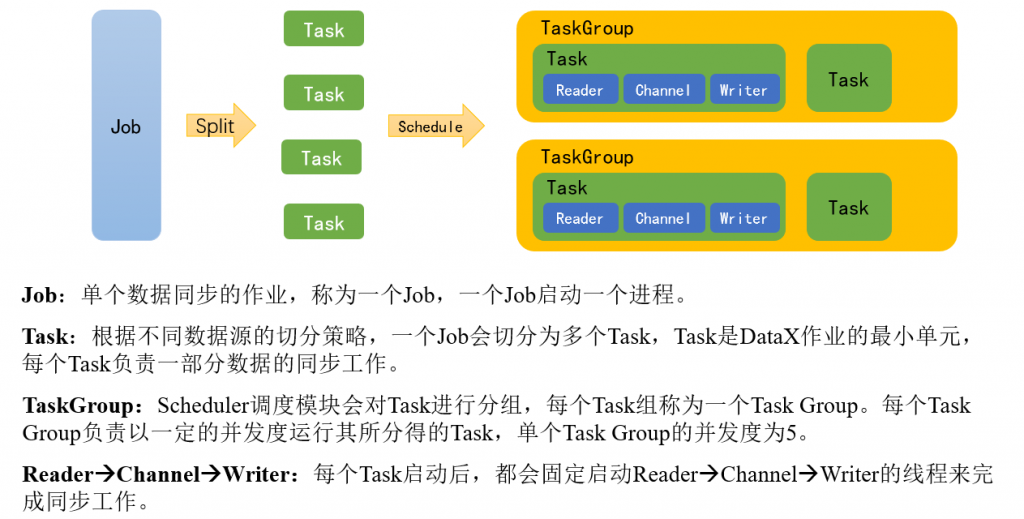
下面用一个DataX作业生命周期的时序图说明DataX的运行流程、核心概念以及每个概念之间的关系。
DataX调度决策思路
举例来说,用户提交了一个DataX作业,并且配置了总的并发度为20,目的是对一个有100张分表的mysql数据源进行同步。DataX的调度决策思路是:
1)DataX Job根据分库分表切分策略,将同步工作分成100个Task。
2)根据配置的总的并发度20,以及每个Task Group的并发度5,DataX计算共需要分配4个TaskGroup。
3)4个TaskGroup平分100个Task,每一个TaskGroup负责运行25个Task。
DataX与Sqoop对比
| 功能 | DataX | Sqoop |
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
DataX部署
1)下载DataX安装包并上传到node01的/opt/apps
下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2)解压datax.tar.gz到/opt/apps
我们需要为每张全量表编写一个DataX的json配置文件,此处以activity_info为例,配置文件内容如下:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"activity_name",
"activity_type",
"activity_desc",
"start_time",
"end_time",
"create_time"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://node01:3306/gmall"
],
"table": [
"activity_info"
]
}
],
"password": "123456",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "activity_name",
"type": "string"
},
{
"name": "activity_type",
"type": "string"
},
{
"name": "activity_desc",
"type": "string"
},
{
"name": "start_time",
"type": "string"
},
{
"name": "end_time",
"type": "string"
},
{
"name": "create_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://node01:8020",
"fieldDelimiter": "\t",
"fileName": "activity_info",
"fileType": "text",
"path": "${targetdir}",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
DataX配置文件生成脚本 方便起见,此处提供了DataX配置文件批量生成脚本,脚本内容及使用方式如下
gen_import_config.py
# ecoding=utf-8
import json
import getopt
import os
import sys
import MySQLdb
#MySQL相关配置,需根据实际情况作出修改
mysql_host = "node01"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "123456"
#HDFS NameNode相关配置,需根据实际情况作出修改
hdfs_nn_host = "node01"
hdfs_nn_port = "8020"
#生成配置文件的目标路径,可根据实际情况作出修改
output_path = "/opt/apps/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])
脚本使用
python gen_import_config.py -d database -t table
或者
gen_import_config.sh
#!/bin/bash
python ~/bin/gen_import_config.py -d gmall -t activity_info
python ~/bin/gen_import_config.py -d gmall -t activity_rule
python ~/bin/gen_import_config.py -d gmall -t base_category1
python ~/bin/gen_import_config.py -d gmall -t base_category2
python ~/bin/gen_import_config.py -d gmall -t base_category3
python ~/bin/gen_import_config.py -d gmall -t base_dic
python ~/bin/gen_import_config.py -d gmall -t base_province
python ~/bin/gen_import_config.py -d gmall -t base_region
python ~/bin/gen_import_config.py -d gmall -t base_trademark
python ~/bin/gen_import_config.py -d gmall -t cart_info
python ~/bin/gen_import_config.py -d gmall -t coupon_info
python ~/bin/gen_import_config.py -d gmall -t sku_attr_value
python ~/bin/gen_import_config.py -d gmall -t sku_info
python ~/bin/gen_import_config.py -d gmall -t sku_sale_attr_value
python ~/bin/gen_import_config.py -d gmall -t spu_info
由于需要使用Python访问Mysql数据库,故需安装驱动,命令如下:
yum install -y MySQL-python
增量表数据同步
Flume配置概述
Flume需要将Kafka中topic_db主题的数据传输到HDFS,故其需选用KafkaSource以及HDFSSink,Channel选用FileChannel。 需要注意的是, HDFSSink需要将不同mysql业务表的数据写到不同的路径,并且路径中应当包含一层日期,用于区分每天的数据。
在node03节点的Flume的job目录下创建kafka_to_hdfs_db.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = node01:9092,node02:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Builder
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/apps/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/apps/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
编写Flume启停脚本
f3.sh
#!/bin/bash
case $1 in
"start")
echo " --------启动 node03业务数据flume-------"
ssh node03"nohup /opt/apps/flume/bin/flume-ng agent -n a1 -c /opt/apps/flume/conf -f /opt/apps/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 node03业务数据flume-------"
ssh node03"ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac
Maxwell配置
修改Maxwell配置文件config.properties,增加mock_date参数,如下
log_level=info
producer=kafka
kafka.bootstrap.servers=node01:9092,node02:9092
#kafka topic配置
kafka_topic=topic_db
#修改该参数后重启Maxwell才可生效
mock_date=2020-06-14
# mysql login info
host=node01
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
增量表首日全量同步
通常情况下,增量表需要在首日进行一次全量同步,后续每日再进行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起见,下面编写一个增量表首日全量同步脚本。
mysql_to_kafka_inc_init.sh
#!/bin/bash
# 该脚本的作用是初始化所有的增量表,只需执行一次
MAXWELL_HOME=/opt/apps/maxwell
import_data() {
$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties
}
case $1 in
"cart_info")
import_data cart_info
;;
"comment_info")
import_data comment_info
;;
"coupon_use")
import_data coupon_use
;;
"favor_info")
import_data favor_info
;;
"order_detail")
import_data order_detail
;;
"order_detail_activity")
import_data order_detail_activity
;;
"order_detail_coupon")
import_data order_detail_coupon
;;
"order_info")
import_data order_info
;;
"order_refund_info")
import_data order_refund_info
;;
"order_status_log")
import_data order_status_log
;;
"payment_info")
import_data payment_info
;;
"refund_payment")
import_data refund_payment
;;
"user_info")
import_data user_info
;;
"all")
import_data cart_info
import_data comment_info
import_data coupon_use
import_data favor_info
import_data order_detail
import_data order_detail_activity
import_data order_detail_coupon
import_data order_info
import_data order_refund_info
import_data order_status_log
import_data payment_info
import_data refund_payment
import_data user_info
;;
esac
采集通道启动/停止脚本
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
hdp.sh start
#启动 Kafka采集集群
kf.sh start
#启动采集 Flume
f1.sh start
#启动日志消费 Flume
f2.sh start
#启动业务消费 Flume
f3.sh start
#启动 maxwell
mxw.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Maxwell
mxw.sh stop
#停止 业务消费Flume
f3.sh stop
#停止 日志消费Flume
f2.sh stop
#停止 日志采集Flume
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
hdp.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
数仓环境准备
Hive安装部署
把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/apps目录下
解压apache-hive-3.1.2-bin.tar.gz到/opt/apps/目录下面,改名
修改/etc/profile.d/my_env.sh,添加环境变量
#HIVE_HOME
export HIVE_HOME=/opt/apps/hive
export PATH=$PATH:$HIVE_HOME/bin
将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/apps/mysql-connector-java-5.1.27-bin.jar /opt/apps/hive/lib/配置Metastore到MySQL
在$HIVE_HOME/conf目录下新建hive-site.xml文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
数据仓库建模的意义
如果把数据看作图书馆里的书,我们希望看到它们在书架上分门别类地放置;如果把数据看作城市的建筑,我们希望城市规划布局合理;如果把数据看作电脑文件和文件夹,我们希望按照自己的习惯有很好的文件夹组织方式,而不是糟糕混乱的桌面,经常为找一个文件而不知所措。
数据模型就是数据组织和存储方法,它强调从业务、数据存取和使用角度合理存储数据。只有将数据有序的组织和存储起来之后,数据才能得到高性能、低成本、高效率、高质量的使用。
高性能:良好的数据模型能够帮助我们快速查询所需要的数据。
低成本:良好的数据模型能减少重复计算,实现计算结果的复用,降低计算成本。
高效率:良好的数据模型能极大的改善用户使用数据的体验,提高使用数据的效率。
高质量:良好的数据模型能改善数据统计口径的混乱,减少计算错误的可能性。
数据仓库建模方法论
ER模型
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
实体关系模型
实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如学生、班级,关系是指两个实体之间的关系,例如学生和班级之间的从属关系。
数据库规范化
数据库规范化是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性。
这一系列范式就是指在设计关系型数据库时,需要遵从的不同的规范。关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
维度模型
数据仓库领域的令一位大师——Ralph Kimball倡导的建模方法为维度建模。维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
注:业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。
下图为一个典型的维度模型,其中位于中心的SalesOrder为事实表,其中保存的是下单这个业务过程的所有记录。位于周围每张表都是维度表,包括Date(日期),Customer(顾客),Product(产品),Location(地区)等,这些维度表就组成了每个订单发生时所处的环境,即何人、何时、在何地下单了何种产品。从图中可以看出,模型相对清晰、简洁。
维度建模以数据分析作为出发点,为数据分析服务,因此它关注的重点的用户如何更快的完成需求分析以及如何实现较好的大规模复杂查询的响应性能。
维度建模理论之事实表
事实表概述
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计。其包含与该业务过程有关的维度引用(维度表外键)以及该业务过程的度量(通常是可累加的数字类型字段)。
事实表特点
事实表通常比较“细长”,即列较少,但行较多,且行的增速快。
事实表分类
事实表有三种类型:分别是事务事实表、周期快照事实表和累积快照事实表,每种事实表都具有不同的特点和适用场景,下面逐个介绍。
事务型事实表
事务型事实表用来记录各业务过程,它保存的是各业务过程的原子操作事件,即最细粒度的操作事件。粒度是指事实表中一行数据所表达的业务细节程度。
事务型事实表可用于分析与各业务过程相关的各项统计指标,由于其保存了最细粒度的记录,可以提供最大限度的灵活性,可以支持无法预期的各种细节层次的统计需求。
设计流程
设计事务事实表时一般可遵循以下四个步骤。
选择业务过程→声明粒度→确认维度→确认事实
选择业务过程
在业务系统中,挑选我们感兴趣的业务过程,业务过程可以概括为一个个不可拆分的行为事件,例如电商交易中的下单,取消订单,付款,退单等,都是业务过程。通常情况下,一个业务过程对应一张事务型事实表。
声明粒度
业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
确定维度
确定维度具体是指,确定与每张事务型事实表相关的维度有哪些。
确定维度时应尽量多的选择与业务过程相关的环境信息。因为维度的丰富程度就决定了维度模型能够支持的指标丰富程度。
确定事实
此处的“事实”一词,指的是每个业务过程的度量值(通常是可累加的数字类型的值,例如:次数、个数、件数、金额等)。
经过上述四个步骤,事务型事实表就基本设计完成了。第一步选择业务过程可以确定有哪些事务型事实表,第二步可以确定每张事务型事实表的每行数据是什么,第三步可以确定每张事务型事实表的维度外键,第四步可以确定每张事务型事实表的度量值字段。
不足
事务型事实表可以保存所有业务过程的最细粒度的操作事件,故理论上其可以支撑与各业务过程相关的各种统计粒度的需求。但对于某些特定类型的需求,其逻辑可能会比较复杂,或者效率会比较低下。例如:
存量型指标
例如商品库存,账户余额等。此处以电商中的虚拟货币为例,虚拟货币业务包含的业务过程主要包括获取货币和使用货币,两个业务过程各自对应一张事务型事实表,一张存储所有的获取货币的原子操作事件,另一张存储所有使用货币的原子操作事件。
假定现有一个需求,要求统计截至当日的各用户虚拟货币余额。由于获取货币和使用货币均会影响到余额,故需要对两张事务型事实表进行聚合,且需要区分两者对余额的影响(加或减),另外需要对两张表的全表数据聚合才能得到统计结果。
可以看到,不论是从逻辑上还是效率上考虑,这都不是一个好的方案。
多事务关联统计
例如,现需要统计最近30天,用户下单到支付的时间间隔的平均值。统计思路应该是找到下单事务事实表和支付事务事实表,过滤出最近30天的记录,然后按照订单id对两张事实表进行关联,之后用支付时间减去下单时间,然后再求平均值。
逻辑上虽然并不复杂,但是其效率较低,应为下单事务事实表和支付事务事实表均为大表,大表join大表的操作应尽量避免。
可以看到,在上述两种场景下事务型事实表的表现并不理想。下面要介绍的另外两种类型的事实表就是为了弥补事务型事实表的不足的。
周期型快照事实表
概述
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,主要用于分析一些存量型(例如商品库存,账户余额)或者状态型(空气温度,行驶速度)指标。
对于商品库存、账户余额这些存量型指标,业务系统中通常就会计算并保存最新结果,所以定期同步一份全量数据到数据仓库,构建周期型快照事实表,就能轻松应对此类统计需求,而无需再对事务型事实表中大量的历史记录进行聚合了。
对于空气温度、行驶速度这些状态型指标,由于它们的值往往是连续的,我们无法捕获其变动的原子事务操作,所以无法使用事务型事实表统计此类需求。而只能定期对其进行采样,构建周期型快照事实表。
设计流程
确定粒度
周期型快照事实表的粒度可由采样周期和维度描述,故确定采样周期和维度后即可确定粒度。
采样周期通常选择每日。
维度可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则可确定维度为仓库和商品。
确定完采样周期和维度后,即可确定该表粒度为每日-仓库-商品。
确认事实
事实也可根据统计指标决定,例如指标为统计每个仓库中每种商品的库存,则事实为商品库存。
事实类型
此处的事实类型是指度量值的类型,而非事实表的类型。事实(度量值)共分为三类,分别是可加事实,半可加事实和不可加事实。
可加事实
可加事实是指可以按照与事实表相关的所有维度进行累加,例如事务型事实表中的事实。
半可加事实
半可加事实是指只能按照与事实表相关的一部分维度进行累加,例如周期型快照事实表中的事实。以上述各仓库中各商品的库存每天快照事实表为例,这张表中的库存事实可以按照仓库或者商品维度进行累加,但是不能按照时间维度进行累加,因为将每天的库存累加起来是没有任何意义的。
不可加事实
不可加事实是指完全不具备可加性,例如比率型事实。不可加事实通常需要转化为可加事实,例如比率可转化为分子和分母。
累积型快照事实表
概述
累计快照事实表是基于一个业务流程中的多个关键业务过程联合处理而构建的事实表,如交易流程中的下单、支付、发货、确认收货业务过程。
累积型快照事实表通常具有多个日期字段,每个日期对应业务流程中的一个关键业务过程(里程碑)。
累积型快照事实表主要用于分析业务过程(里程碑)之间的时间间隔等需求。例如前文提到的用户下单到支付的平均时间间隔,使用累积型快照事实表进行统计,就能避免两个事务事实表的关联操作,从而变得十分简单高效。
设计流程
累积型快照事实表的设计流程同事务型事实表类似,也可采用以下四个步骤,下面重点描述与事务型事实表的不同之处。
选择业务过程→声明粒度→确认维度→确认事实。
选择业务过程
选择一个业务流程中需要关联分析的多个关键业务过程,多个业务过程对应一张累积型快照事实表。
声明粒度
精确定义每行数据表示的是什么,尽量选择最小粒度。
确认维度
选择与各业务过程相关的维度,需要注意的是,每各业务过程均需要一个日期维度。
确认事实
选择各业务过程的度量值。
维度建模理论之维度表
维度表概述
维度表是维度建模的基础和灵魂。前文提到,事实表紧紧围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
维度表设计步骤
确定维度(表)
在设计事实表时,已经确定了与每个事实表相关的维度,理论上每个相关维度均需对应一张维度表。需要注意到,可能存在多个事实表与同一个维度都相关的情况,这种情况需保证维度的唯一性,即只创建一张维度表。另外,如果某些维度表的维度属性很少,例如只有一个**名称,则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。
确定主维表和相关维表
此处的主维表和相关维表均指业务系统中与某维度相关的表。例如业务系统中与商品相关的表有sku_info,spu_info,base_trademark,base_category3,base_category2,base_category1等,其中sku_info就称为商品维度的主维表,其余表称为商品维度的相关维表。维度表的粒度通常与主维表相同。
确定维度属性
确定维度属性即确定维度表字段。维度属性主要来自于业务系统中与该维度对应的主维表和相关维表。维度属性可直接从主维表或相关维表中选择,也可通过进一步加工得到。
确定维度属性时,需要遵循以下要求:
尽可能生成丰富的维度属性
维度属性是后续做分析统计时的查询约束条件、分组字段的基本来源,是数据易用性的关键。维度属性的丰富程度直接影响到数据模型能够支持的指标的丰富程度。
尽量不使用编码,而使用明确的文字说明,一般可以编码和文字共存。
尽量沉淀出通用的维度属性
有些维度属性的获取需要进行比较复杂的逻辑处理,例如需要通过多个字段拼接得到。为避免后续每次使用时的重复处理,可将这些维度属性沉淀到维度表中。
维度设计要点
规范化与反规范化
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时,如果对其进行规范化,得到的维度模型称为雪花模型,如果对其进行反规范化,得到的模型称为星型模型。
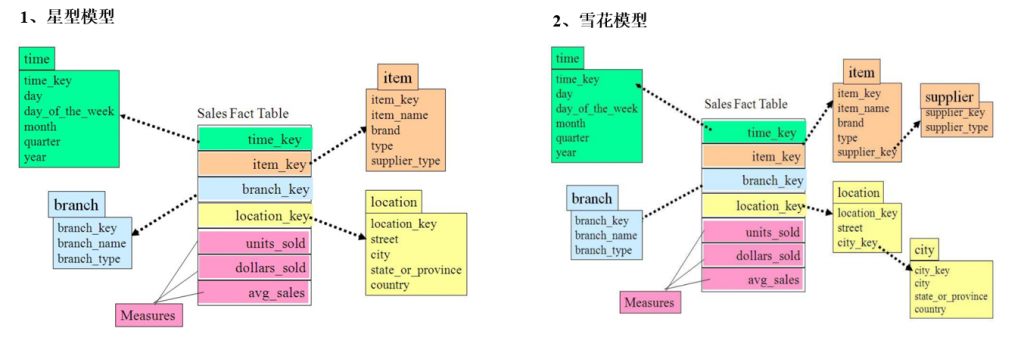
数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,维度表一般是很不规范化的。
数据仓库分层规划
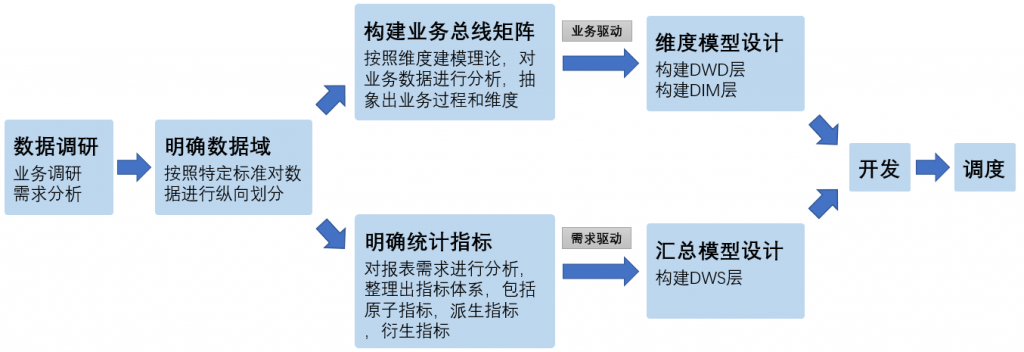
优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划。

数据仓库构建流程
以下是构建数据仓库的完整流程。
数据仓库运行环境
Hive引擎简介
Hive引擎包括:默认MR、Tez、Spark。
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
Hive on Spark配置
(1)兼容性说明
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz,改名,修改环境变量
# SPARK_HOME
export SPARK_HOME=/opt/apps/spark
export PATH=$PATH:$SPARK_HOME/bin
在hive中创建spark配置文件
spark-defaults.conf
添加
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
上传并解压spark-3.0.0-bin-without-hadoop.tgz
上传Spark纯净版jar包到HDFS
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
修改hive-site.xml文件
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://node01:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
在node01的/opt/apps/hadoop/etc/hadoop/capacity-scheduler.xml文件中修改如下参数值并分发
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
启动HiveServer2
hiveserver2
配置DataGrip连接
所有属性配置,和Hive的beeline客户端配置一致即可。初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。
创建数据库
模拟数据准备
通常企业在开始搭建数仓时,业务系统中会存在历史数据,一般是业务数据库存在历史数据,而用户行为日志无历史数据。假定数仓上线的日期为2020-06-14,为模拟真实场景,需准备以下数据。
注:在执行以下操作之前,先将HDFS上/origin_data路径下之前的数据删除。
用户行为日志
用户行为日志,一般是没有历史数据的,故日志只需要准备2020-06-14一天的数据。具体操作如下:
(1)启动日志采集通道,包括Flume、Kafak等
(2)修改两个日志服务器(node01、node02)中的
/opt/apps/applog/application.yml配置文件,将mock.date参数改为2020-06-14。
(3)执行日志生成脚本lg.sh。
(4)观察HDFS是否出现相应文件。
业务数据
业务数据一般存在历史数据,此处需准备2020-06-10至2020-06-14的数据。具体操作如下。
生成模拟数据
修改node01节点上的/opt/apps/db_log/application.properties文件,将mock.date、mock.clear,mock.clear.user三个参数调整为如图所示的值。
执行模拟生成业务数据的命令,生成第一天2020-06-10的历史数据。
java -jar gmall2020-mock-db-2021-01-22.jar
修改/opt/apps/db_log/application.properties文件,将mock.date、mock.clear,mock.clear.user三个参数调整为如图所示的值。
4执行模拟生成业务数据的命令,生成第二天2020-06-11的历史数据。
java -jar gmall2020-mock-db-2021-10-10.jar
5之后只修改/opt/apps/db_log/application.properties文件中的mock.date参数,依次改为2020-06-12,2020-06-13,2020-06-14,并分别生成对应日期的数据。
全量表同步
执行全量表同步脚本
mysql_to_hdfs_full.sh all 2020-06-14
观察HDFS上是否出现全量表数据
增量表首日全量同步
清除Maxwell断点记录
由于Maxwell支持断点续传,而上述重新生成业务数据的过程,会产生大量的binlog操作日志,这些日志我们并不需要。故此处需清除Maxwell的断点记录,另其从binlog最新的位置开始采集。
关闭Maxwell。
mxw.sh stop
清空Maxwell数据库,相当于初始化Maxwell。
mysql>
drop table maxwell.bootstrap;
drop table maxwell.columns;
drop table maxwell.databases;
drop table maxwell.heartbeats;
drop table maxwell.positions;
drop table maxwell.schemas;
drop table maxwell.tables;
修改Maxwell配置文件中的mock_date参数
vim /opt/apps/maxwell/config.properties
mock_date=2020-06-14
启动增量表数据通道,包括Maxwell、Kafka、Flume
执行增量表首日全量同步脚本
mysql_to_kafka_inc_init.sh all
观察HDFS上是否出现全量表数据
数仓开发之ODS层
ODS层的设计要点如下:
(1)ODS层的表结构设计依托于从业务系统同步过来的数据结构。
(2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
(3)ODS层表名的命名规范为:ods_表名_单分区增量全量标识(inc/full)。
日志表
DROP TABLE IF EXISTS ods_log_inc;
CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id
:STRING,source_type :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',
`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id
:STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms
:BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/';
活动信息表(全量表)
DROP TABLE IF EXISTS ods_activity_info_full;
CREATE EXTERNAL TABLE ods_activity_info_full
(
`id` STRING COMMENT '活动id',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_activity_info_full/';
活动规则表(全量表)
DROP TABLE IF EXISTS ods_activity_rule_full;
CREATE EXTERNAL TABLE ods_activity_rule_full
(
`id` STRING COMMENT '编号',
`activity_id` STRING COMMENT '类型',
`activity_type` STRING COMMENT '活动类型',
`condition_amount` DECIMAL(16, 2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16, 2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '优惠折扣',
`benefit_level` STRING COMMENT '优惠级别'
) COMMENT '活动规则表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_activity_rule_full/';
一级品类表(全量表)
DROP TABLE IF EXISTS ods_base_category1_full;
CREATE EXTERNAL TABLE ods_base_category1_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '分类名称'
) COMMENT '一级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category1_full/';
二级品类表(全量表)
DROP TABLE IF EXISTS ods_base_category2_full;
CREATE EXTERNAL TABLE ods_base_category2_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类编号'
) COMMENT '二级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category2_full/';
三级品类表(全量表)
DROP TABLE IF EXISTS ods_base_category3_full;
CREATE EXTERNAL TABLE ods_base_category3_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类编号'
) COMMENT '三级品类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_category3_full/';
编码字典表(全量表)
DROP TABLE IF EXISTS ods_base_dic_full;
CREATE EXTERNAL TABLE ods_base_dic_full
(
`dic_code` STRING COMMENT '编号',
`dic_name` STRING COMMENT '编码名称',
`parent_code` STRING COMMENT '父编号',
`create_time` STRING COMMENT '创建日期',
`operate_time` STRING COMMENT '修改日期'
) COMMENT '编码字典表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_dic_full/';
省份表(全量表)
DROP TABLE IF EXISTS ods_base_province_full;
CREATE EXTERNAL TABLE ods_base_province_full
(
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省份名称',
`region_id` STRING COMMENT '地区ID',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用'
) COMMENT '省份表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_province_full/';
地区表(全量表)
DROP TABLE IF EXISTS ods_base_region_full;
CREATE EXTERNAL TABLE ods_base_region_full
(
`id` STRING COMMENT '编号',
`region_name` STRING COMMENT '地区名称'
) COMMENT '地区表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_region_full/';
品牌表(全量表)
DROP TABLE IF EXISTS ods_base_trademark_full;
CREATE EXTERNAL TABLE ods_base_trademark_full
(
`id` STRING COMMENT '编号',
`tm_name` STRING COMMENT '品牌名称',
`logo_url` STRING COMMENT '品牌logo的图片路径'
) COMMENT '品牌表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_base_trademark_full/';
购物车表(全量表)
DROP TABLE IF EXISTS ods_cart_info_full;
CREATE EXTERNAL TABLE ods_cart_info_full
(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'sku_id',
`cart_price` DECIMAL(16, 2) COMMENT '放入购物车时价格',
`sku_num` BIGINT COMMENT '数量',
`img_url` BIGINT COMMENT '商品图片地址',
`sku_name` STRING COMMENT 'sku名称 (冗余)',
`is_checked` STRING COMMENT '是否被选中',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`is_ordered` STRING COMMENT '是否已经下单',
`order_time` STRING COMMENT '下单时间',
`source_type` STRING COMMENT '来源类型',
`source_id` STRING COMMENT '来源编号'
) COMMENT '购物车全量表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_cart_info_full/';
优惠券信息表(全量表)
DROP TABLE IF EXISTS ods_coupon_info_full;
CREATE EXTERNAL TABLE ods_coupon_info_full
(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type` STRING COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` DECIMAL(16, 2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16, 2) COMMENT '减金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '折扣',
`create_time` STRING COMMENT '创建时间',
`range_type` STRING COMMENT '范围类型 1、商品 2、品类 3、品牌',
`limit_num` BIGINT COMMENT '最多领用次数',
`taken_count` BIGINT COMMENT '已领用次数',
`start_time` STRING COMMENT '开始领取时间',
`end_time` STRING COMMENT '结束领取时间',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_coupon_info_full/';
商品平台属性表(全量表)
DROP TABLE IF EXISTS ods_sku_attr_value_full;
CREATE EXTERNAL TABLE ods_sku_attr_value_full
(
`id` STRING COMMENT '编号',
`attr_id` STRING COMMENT '平台属性ID',
`value_id` STRING COMMENT '平台属性值ID',
`sku_id` STRING COMMENT '商品ID',
`attr_name` STRING COMMENT '平台属性名称',
`value_name` STRING COMMENT '平台属性值名称'
) COMMENT 'sku平台属性表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_attr_value_full/';
商品表(全量表)
DROP TABLE IF EXISTS ods_sku_info_full;
CREATE EXTERNAL TABLE ods_sku_info_full
(
`id` STRING COMMENT 'skuId',
`spu_id` STRING COMMENT 'spuid',
`price` DECIMAL(16, 2) COMMENT '价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`tm_id` STRING COMMENT '品牌id',
`category3_id` STRING COMMENT '品类id',
`sku_default_igm` STRING COMMENT '商品图片地址',
`is_sale` STRING COMMENT '是否在售',
`create_time` STRING COMMENT '创建时间'
) COMMENT 'SKU商品表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_info_full/';
商品销售属性值表(全量表)
DROP TABLE IF EXISTS ods_sku_sale_attr_value_full;
CREATE EXTERNAL TABLE ods_sku_sale_attr_value_full
(
`id` STRING COMMENT '编号',
`sku_id` STRING COMMENT 'sku_id',
`spu_id` STRING COMMENT 'spu_id',
`sale_attr_value_id` STRING COMMENT '销售属性值id',
`sale_attr_id` STRING COMMENT '销售属性id',
`sale_attr_name` STRING COMMENT '销售属性名称',
`sale_attr_value_name` STRING COMMENT '销售属性值名称'
) COMMENT 'sku销售属性名称'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_sku_sale_attr_value_full/';
SPU表(全量表)
DROP TABLE IF EXISTS ods_spu_info_full;
CREATE EXTERNAL TABLE ods_spu_info_full
(
`id` STRING COMMENT 'spu_id',
`spu_name` STRING COMMENT 'spu名称',
`description` STRING COMMENT '描述信息',
`category3_id` STRING COMMENT '品类id',
`tm_id` STRING COMMENT '品牌id'
) COMMENT 'SPU商品表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
NULL DEFINED AS ''
LOCATION '/warehouse/gmall/ods/ods_spu_info_full/';
购物车表(增量表)
DROP TABLE IF EXISTS ods_cart_info_inc;
CREATE EXTERNAL TABLE ods_cart_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,user_id :STRING,sku_id :STRING,cart_price :DECIMAL(16, 2),sku_num :BIGINT,img_url :STRING,sku_name
:STRING,is_checked :STRING,create_time :STRING,operate_time :STRING,is_ordered :STRING,order_time
:STRING,source_type :STRING,source_id :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '购物车增量表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_cart_info_inc/';
评论表(增量表)
DROP TABLE IF EXISTS ods_comment_info_inc;
CREATE EXTERNAL TABLE ods_comment_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,user_id :STRING,nick_name :STRING,head_img :STRING,sku_id :STRING,spu_id :STRING,order_id
:STRING,appraise :STRING,comment_txt :STRING,create_time :STRING,operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '评价表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_comment_info_inc/';
优惠券领用表(增量表)
DROP TABLE IF EXISTS ods_coupon_use_inc;
CREATE EXTERNAL TABLE ods_coupon_use_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,coupon_id :STRING,user_id :STRING,order_id :STRING,coupon_status :STRING,get_time :STRING,using_time
:STRING,used_time :STRING,expire_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '优惠券领用表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_coupon_use_inc/';
收藏表(增量表)
DROP TABLE IF EXISTS ods_favor_info_inc;
CREATE EXTERNAL TABLE ods_favor_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,user_id :STRING,sku_id :STRING,spu_id :STRING,is_cancel :STRING,create_time :STRING,cancel_time
:STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '收藏表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_favor_info_inc/';
订单明细表(增量表)
DROP TABLE IF EXISTS ods_order_detail_inc;
CREATE EXTERNAL TABLE ods_order_detail_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,order_id :STRING,sku_id :STRING,sku_name :STRING,img_url :STRING,order_price
:DECIMAL(16, 2),sku_num :BIGINT,create_time :STRING,source_type :STRING,source_id :STRING,split_total_amount
:DECIMAL(16, 2),split_activity_amount :DECIMAL(16, 2),split_coupon_amount
:DECIMAL(16, 2)> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单明细表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_inc/';
订单明细活动关联表(增量表)
DROP TABLE IF EXISTS ods_order_detail_activity_inc;
CREATE EXTERNAL TABLE ods_order_detail_activity_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,order_id :STRING,order_detail_id :STRING,activity_id :STRING,activity_rule_id :STRING,sku_id
:STRING,create_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单明细活动关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_activity_inc/';
订单明细优惠券关联表(增量表)
DROP TABLE IF EXISTS ods_order_detail_coupon_inc;
CREATE EXTERNAL TABLE ods_order_detail_coupon_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,order_id :STRING,order_detail_id :STRING,coupon_id :STRING,coupon_use_id :STRING,sku_id
:STRING,create_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单明细优惠券关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_detail_coupon_inc/';
订单表(增量表)
DROP TABLE IF EXISTS ods_order_info_inc;
CREATE EXTERNAL TABLE ods_order_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,consignee :STRING,consignee_tel :STRING,total_amount :DECIMAL(16, 2),order_status :STRING,user_id
:STRING,payment_way :STRING,delivery_address :STRING,order_comment :STRING,out_trade_no :STRING,trade_body
:STRING,create_time :STRING,operate_time :STRING,expire_time :STRING,process_status :STRING,tracking_no
:STRING,parent_order_id :STRING,img_url :STRING,province_id :STRING,activity_reduce_amount
:DECIMAL(16, 2),coupon_reduce_amount :DECIMAL(16, 2),original_total_amount :DECIMAL(16, 2),freight_fee
:DECIMAL(16, 2),freight_fee_reduce :DECIMAL(16, 2),refundable_time :DECIMAL(16, 2)> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '订单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_info_inc/';
退单表(增量表)
DROP TABLE IF EXISTS ods_order_refund_info_inc;
CREATE EXTERNAL TABLE ods_order_refund_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,user_id :STRING,order_id :STRING,sku_id :STRING,refund_type :STRING,refund_num :BIGINT,refund_amount
:DECIMAL(16, 2),refund_reason_type :STRING,refund_reason_txt :STRING,refund_status :STRING,create_time
:STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_refund_info_inc/';
订单状态流水表(增量表)
DROP TABLE IF EXISTS ods_order_status_log_inc;
CREATE EXTERNAL TABLE ods_order_status_log_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,order_id :STRING,order_status :STRING,operate_time :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_order_status_log_inc/';
支付表(增量表)
DROP TABLE IF EXISTS ods_payment_info_inc;
CREATE EXTERNAL TABLE ods_payment_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,out_trade_no :STRING,order_id :STRING,user_id :STRING,payment_type :STRING,trade_no
:STRING,total_amount :DECIMAL(16, 2),subject :STRING,payment_status :STRING,create_time :STRING,callback_time
:STRING,callback_content :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '支付表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_payment_info_inc/';
退款表(增量表)
DROP TABLE IF EXISTS ods_refund_payment_inc;
CREATE EXTERNAL TABLE ods_refund_payment_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,out_trade_no :STRING,order_id :STRING,sku_id :STRING,payment_type :STRING,trade_no :STRING,total_amount
:DECIMAL(16, 2),subject :STRING,refund_status :STRING,create_time :STRING,callback_time :STRING,callback_content
:STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退款表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_refund_payment_inc/';
用户表(增量表)
DROP TABLE IF EXISTS ods_user_info_inc;
CREATE EXTERNAL TABLE ods_user_info_inc
(
`type` STRING COMMENT '变动类型',
`ts` BIGINT COMMENT '变动时间',
`data` STRUCT<id :STRING,login_name :STRING,nick_name :STRING,passwd :STRING,name :STRING,phone_num :STRING,email
:STRING,head_img :STRING,user_level :STRING,birthday :STRING,gender :STRING,create_time :STRING,operate_time
:STRING,status :STRING> COMMENT '数据',
`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_user_info_inc/';
数仓开发之DIM层
DIM层设计要点:
(1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
(2)DIM层的数据存储格式为orc列式存储+snappy压缩。
(3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)
商品维度表
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(
`id` STRING COMMENT 'sku_id',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'spu编号',
`spu_name` STRING COMMENT 'spu名称',
`category3_id` STRING COMMENT '三级分类id',
`category3_name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类id',
`category2_name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_sku_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
优惠券维度表
DROP TABLE IF EXISTS dim_coupon_full;
CREATE EXTERNAL TABLE dim_coupon_full
(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type_code` STRING COMMENT '购物券类型编码',
`coupon_type_name` STRING COMMENT '购物券类型名称',
`condition_amount` DECIMAL(16, 2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16, 2) COMMENT '减金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '折扣',
`benefit_rule` STRING COMMENT '优惠规则:满元*减*元,满*件打*折',
`create_time` STRING COMMENT '创建时间',
`range_type_code` STRING COMMENT '优惠范围类型编码',
`range_type_name` STRING COMMENT '优惠范围类型名称',
`limit_num` BIGINT COMMENT '最多领取次数',
`taken_count` BIGINT COMMENT '已领取次数',
`start_time` STRING COMMENT '可以领取的开始日期',
`end_time` STRING COMMENT '可以领取的结束日期',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_coupon_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
活动维度表
DROP TABLE IF EXISTS dim_activity_full;
CREATE EXTERNAL TABLE dim_activity_full
(
`activity_rule_id` STRING COMMENT '活动规则ID',
`activity_id` STRING COMMENT '活动ID',
`activity_name` STRING COMMENT '活动名称',
`activity_type_code` STRING COMMENT '活动类型编码',
`activity_type_name` STRING COMMENT '活动类型名称',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间',
`condition_amount` DECIMAL(16, 2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16, 2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '优惠折扣',
`benefit_rule` STRING COMMENT '优惠规则',
`benefit_level` STRING COMMENT '优惠级别'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_activity_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
地区维度表
DROP TABLE IF EXISTS dim_province_full;
CREATE EXTERNAL TABLE dim_province_full
(
`id` STRING COMMENT 'id',
`province_name` STRING COMMENT '省市名称',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用',
`region_id` STRING COMMENT '地区id',
`region_name` STRING COMMENT '地区名称'
) COMMENT '地区维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_province_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
日期维度表
DROP TABLE IF EXISTS dim_date;
CREATE EXTERNAL TABLE dim_date
(
`date_id` STRING COMMENT '日期ID',
`week_id` STRING COMMENT '周ID,一年中的第几周',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '一年中的第几月',
`quarter` STRING COMMENT '一年中的第几季度',
`year` STRING COMMENT '年份',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_date/'
TBLPROPERTIES ('orc.compress' = 'snappy');
用户维度表
DROP TABLE IF EXISTS dim_user_zip;
CREATE EXTERNAL TABLE dim_user_zip
(
`id` STRING COMMENT '用户id',
`login_name` STRING COMMENT '用户名称',
`nick_name` STRING COMMENT '用户昵称',
`name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号码',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户等级',
`birthday` STRING COMMENT '生日',
`gender` STRING COMMENT '性别',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_user_zip/'
TBLPROPERTIES ('orc.compress' = 'snappy');
用户留存率
留存分析一般包含新增留存和活跃留存分析。
新增留存分析是分析某天的新增用户中,有多少人有后续的活跃行为。活跃留存分析是分析某天的活跃用户中,有多少人有后续的活跃行为。
留存分析是衡量产品对用户价值高低的重要指标。
此处要求统计新增留存率,新增留存率具体是指留存用户数与新增用户数的比值,例如2020-06-14新增100个用户,1日之后(2020-06-15)这100人中有80个人活跃了,那2020-06-14的1日留存数则为80,2020-06-14的1日留存率则为80%。
用户行为漏斗分析
漏斗分析是一个数据分析模型,它能够科学反映一个业务过程从起点到终点各阶段用户转化情况。由于其能将各阶段环节都展示出来,故哪个阶段存在问题,就能一目了然。
工作流调度实操
由于DolphinScheduler集群模式启动进程较多,对虚拟机内存要求较高。故下面提供两种方式,可根据虚拟机内存情况进行选择。
Superset入门
Apache Superset是一个现代的数据探索和可视化平台。它功能强大且十分易用,可对接各种数据源,包括很多现代的大数据分析引擎,拥有丰富的图表展示形式,并且支持自定义仪表盘。
Superset安装
Superset官网地址:http://superset.apache.org/
Superset是由Python语言编写的Web应用,要求Python3.7的环境。
安装Miniconda
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同Python版本的软件包及其依赖,并能够在不同的Python环境之间切换,Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等,Miniconda包括Conda、Python。
此处,我们不需要如此多的工具包,故选择MiniConda。
下载地址:https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
Miniconda安装完成后,每次打开终端都会激活其默认的base环境,我们可通过以下命令,禁止激活默认base环境。
配置conda国内镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --set show_channel_urls yes
conda create --name superset python=3.7
conda activate superset
Superset部署
安装Superset之前,需安装以下所需依赖。
yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
安装(更新)setuptools和pip
pip install --upgrade setuptools pip -i https://pypi.douban.com/simple/
安装Supetset
pip install apache-superset -i https://pypi.douban.com/simple/
pip install apache-superset --trusted-host https://repo.huaweicloud.com -i https://repo.huaweicloud.com/repository/pypi/simple
初始化Supetset数据库
superset db upgrade
创建管理员用户
export FLASK_APP=superset
superset fab create-admin
superset init
安装gunicorn
pip install gunicorn -i https://pypi.douban.com/simple/
启动
gunicorn --workers 5 --timeout 120 --bind hadoop102:8787 "superset.app:create_app()" --daemon
登录Superset登录Superset
访问http://node01:8787,并使用创建的管理员账号进行登录。
对接MySQL数据源
安装依赖
conda install mysqlclient
重启Superset
superset.sh restart
Database配置
Step1:点击Data/Databases。
Step2:点击+DATABASE。
Step3:点击填写Database及SQL Alchemy URI
mysql://root:000000@node01:3306/gmall_report?charset=utf8
Step4:点击Test Connection,出现“Connection looks good!”提示即表示连接成功
Step5:点击ADD
Table配置
Step1:点击Data/Datasets
Step3:配置Table
创建空白仪表盘
点击Dashboards/+DASHBOARDS
创建图表
点击Charts/+CHART
选数据源及图表类型
选择何使的图表类型